
XGBoost(eXtreme Gradient Boosting)はワシントン大学の博士課程在籍中だった陳天奇(Tianqi Chen)氏が2014年に開発を始めたオープンソースの勾配ブースティング決定木ライブラリです。従来のGBDT実装を正則化項・並列計算・スパース対応・キャッシュ最適化で徹底的に磨き込み、2015年以降のKaggleコンペで歴代の優勝ソリューションの大半に名前が登場する事実上の業界標準として君臨してきました。C++コアにPython・R・Java・Scala・Juliaなど複数言語のバインディングを備え、表形式データの分類・回帰タスクで広く採用されています。
この記事の目次
- 三層で支える勾配ブースティングの核
- 誕生からデファクト確立までの歩み
- 現場で頼られる典型ユースケース
- LightGBM・CatBoostとの違い
- まとめ
三層で支える勾配ブースティングの核
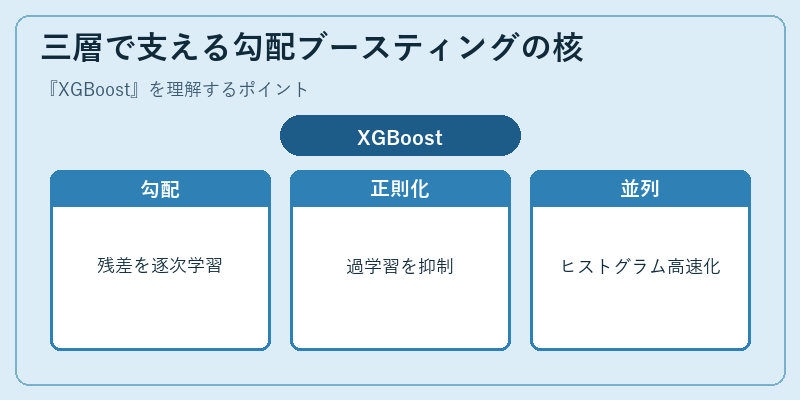
XGBoostの中核は、決定木を一本ずつ順番に追加し、直前までの予測残差を新しい木に学ばせる勾配ブースティングの仕組みです。ジェロム・フリードマンが1999年に提案したGBDTの考え方を踏襲しつつ、損失関数の二次微分(ヘッセ行列)まで用いた近似最適化を導入することで、分岐点探索を解析的な閉じた式で評価できるようにしました。これにより同じ木構造の探索でも収束が速く、より精緻な分岐が選べるようになっています。
実装面ではL1・L2正則化項を目的関数に組み込み、葉ノードの重みと木の複雑さを直接ペナルティ化することで過学習を抑制します。さらに特徴量をビンに区切るヒストグラムベースの分岐探索、列方向のキャッシュ最適化、欠損値を自動で片側に流すスパース対応など、数百万行規模の表データでも実用的な速度で訓練できるエンジニアリングが積み重ねられています。GPUバックエンドや分散学習も標準で備わります。
誕生からデファクト確立までの歩み

XGBoostの原型は2014年、当時ワシントン大学の博士課程に在籍していた陳天奇氏が研究用に書いたC++コードでした。翌2015年にKaggleで開催されたHiggs Boson Machine Learning Challengeで上位入賞者の多くが採用したことで一気に注目を集め、陳氏は同年にPython・Rバインディングを整え、コミュニティ主導のDMLC(Distributed Machine Learning Community)へとプロジェクトを移管します。2016年のKDDで「XGBoost: A Scalable Tree Boosting System」を発表し、被引用数は数万件規模に達しました。
以降XGBoostは、scikit-learn互換のEstimator API、DaskやSparkとの統合、GPU対応(gpu_hist、後にhist+device=’cuda’)、Apache 2.0ライセンスでの配布などを通じて、データサイエンスの教科書・コンペ・実務のどこにでも顔を出す定番ライブラリになりました。陳氏自身はその後Apache TVMやMXNetといった別プロジェクトを牽引していますが、XGBoostは多数のメンテナによって2024年以降も活発に更新が続けられています。
現場で頼られる典型ユースケース

XGBoostが最も力を発揮するのは、行と列が明確に定義された表形式の業務データです。金融分野では与信スコアリングや解約予測、デフォルト確率のモデリングに用いられ、欠損値や外れ値の多いデータでも前処理の手間を抑えて高精度を出せる点が評価されています。広告・EC分野では、ユーザー属性と行動ログを結合した特徴量からクリック率(CTR)や購入確率を推定し、入札ロジックやレコメンドの再ランキングに組み込む使い方が定着しています。
製造業や小売では需要予測・在庫最適化、輸送会社では到着時刻予測、医療では再発リスクや入院期間の予測など、「ディープラーニングを持ち出すほど画像・音声らしさのない、構造化データの予測」という領域でXGBoostは依然として第一候補です。feature_importanceやSHAP値による寄与度可視化と組み合わせれば、モデルの説明責任が問われる与信・医療領域でも納得感のある説明が用意でき、運用に乗せやすい点も支持されています。
LightGBM・CatBoostとの違い

勾配ブースティング系ライブラリにはMicrosoftのLightGBM(2016年)、YandexのCatBoost(2017年)という有力な後発が存在します。LightGBMは葉単位で深く成長させるleaf-wise木とヒストグラム最適化で、同じ精度ならXGBoostより数倍高速というベンチマーク結果が報告されることが多く、超大規模データではこちらが選ばれる傾向にあります。CatBoostはカテゴリ変数のターゲット統計量計算を訓練ループに組み込む独自設計で、前処理を簡素化できる点が魅力です。
それでもXGBoostが第一候補に挙がり続けるのは、リリースから10年以上の運用実績、豊富な学術引用、各種クラウドや機械学習プラットフォームでのサポートの厚さ、そして「とりあえずXGBoostで動かせばベースラインが取れる」という共通言語的な地位が確立しているためです。プロジェクト初期はXGBoostでベースラインを取り、データ規模やカテゴリ変数の比率に応じてLightGBM・CatBoostへ乗り換えるという使い分けが、実務で広く採られています。
まとめ
XGBoostは2014年に陳天奇氏が世に出した勾配ブースティング決定木ライブラリで、Kaggleと業務データ分析の双方で長く第一候補の座を保ってきました。正則化・並列化・GPU対応を備えた成熟した実装は、後発のLightGBMやCatBoostが台頭した今も「まず動かす一本」として現場で頼られ続けています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント