
CatBoost(Categorical Boosting)はロシアの検索・ITサービス大手Yandexが2017年に公開した勾配ブースティング決定木ライブラリです。高カーディナリティのカテゴリ変数を前処理なしで直接扱える設計と、対称(oblivious)決定木による高速推論が特徴で、Yandexの検索ランキングや広告配信、レコメンドエンジンの本番系で実戦投入されてきた実装をオープンソースとして公開しています。Apache 2.0ライセンス、Python・R・C++ APIに加え、CPU・GPU・分散学習を一通りサポートします。
この記事の目次
- 他のGBDTと一線を画す三本柱
- Yandex本番系から世界へ
- カテゴリ列が支配的な現場で効く
- XGBoost・LightGBMとの違い
- まとめ
他のGBDTと一線を画す三本柱
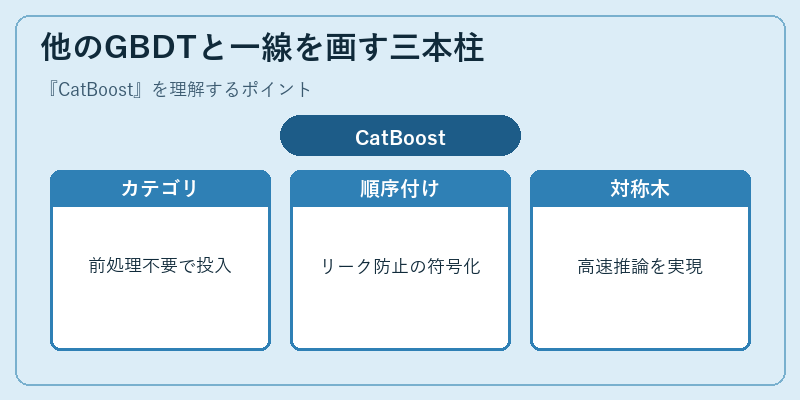
CatBoostの最大の特徴は、文字列やID型のカテゴリ変数をそのまま入力として受け取り、内部で動的に数値化してくれる点です。従来のGBDTでは事前にOne-Hotエンコードやターゲットエンコードを行う必要があり、特に高カーディナリティの列ではメモリと精度の両面で工夫が必要でした。CatBoostはこれを学習ループの内側に取り込み、「カテゴリの組合せ特徴量」までも自動生成することで、特徴量エンジニアリングの工数を大幅に減らしてくれます。
その肝になるのが「Ordered Target Statistics」と呼ばれる順序付きターゲット符号化です。通常のターゲットエンコードでは、自分自身のラベルが符号化に混ざるリーク(target leakage)が起きやすいのですが、CatBoostでは学習データをランダムに並べ、各サンプルより前の行だけから統計量を計算することでこの問題を回避します。推論側では、全葉が同じ深さで分岐条件も同一の対称(oblivious)木を採用し、ベクトル化された高速評価が可能です。
Yandex本番系から世界へ

CatBoostの源流は、Yandexが2009年に検索ランキングへ導入した独自勾配ブースティングシステムMatrixNetにさかのぼります。MatrixNetは検索品質を大きく押し上げ、その後の広告・レコメンド・気象予測など同社の機械学習スタックの基盤となりました。「これを社外でも使えるようにしよう」という社内プロジェクトとして整理されたのがCatBoostで、2017年7月にGitHubで初版が公開され、創発に関わったAnna Veronika Dorogush氏ら研究者がプロジェクトを主導しています。
2018年のKDDワークショップで「CatBoost: gradient boosting with categorical features support」が発表されると、Kaggleコンペでも上位ソリューションに採用が広がりました。近年はAmazon SageMaker、Google Vertex AI、Hugging Face Hubなど主要MLOps基盤からも利用でき、高カーディナリティのIDが多いリテール・通信・金融分野で、XGBoost・LightGBMと並ぶ標準的な選択肢として定着しています。
カテゴリ列が支配的な現場で効く

CatBoostが最も適しているのは、ユーザーID・商品ID・地域コード・キャンペーン名のように、値の種類が多いカテゴリ列が予測に強く効くドメインです。ECサイトのレコメンドでは、過去の購買履歴とカテゴリ階層・ブランド・色などを大量に投入しても前処理に追われずに済み、「とりあえずCatBoostに全列を渡してベースライン」という運用が成り立ちます。サブスクリプションサービスの解約予測でも、契約プラン・利用機能・地域・代理店のような離散変数が多い場面で力を発揮します。
Yandex自身が天気予報サービスYandex.Weatherにおいて気象観測点と地形カテゴリを扱う気象予測モデルにCatBoostを利用しており、オフライン広告のCV予測、保険査定のリスク評価、電力需要予測といった「離散変数と連続変数が混在し、解釈性も求められる」業務で採用が増えています。対称木のおかげで推論レイテンシが安定するため、リアルタイム推論を含む本番システムにも乗せやすい点も評価されています。
XGBoost・LightGBMとの違い

XGBoostは全方位に強い「最大公約数」、LightGBMは大規模データの速さ、CatBoostはカテゴリ変数と推論性能という具合に、GBDT御三家には明確なキャラクター差があります。CatBoostは初期設定のままでも他ライブラリと拮抗する精度が出やすく、ハイパーパラメータチューニングに割ける時間が限られたPoCや業務システムで助けになります。一方で、純粋に数値特徴量だけの大規模回帰タスクではLightGBMの方が速い場面が多く、選択は問題設定に応じた使い分けになります。
実務では、データに高カーディナリティのIDや文字列カテゴリが多いか、推論レイテンシをどれだけ詰めたいかを判断軸に、CatBoostとLightGBMの両方で同じパイプラインを回し、精度・速度・運用しやすさを総合比較する流れが定着してきました。三者ともscikit-learn互換APIを備えるため、Optunaなどの自動チューニングフレームワーク経由で同じ条件下で比較できる点も、GBDT選定を健全な議論にしてくれています。
まとめ
CatBoostは2017年にYandexが公開した、カテゴリ変数に強い勾配ブースティングライブラリです。順序付きターゲット符号化と対称木による高速推論、デフォルト設定での精度の高さを武器に、XGBoost・LightGBMと並ぶGBDT御三家の一角として、IDだらけの業務データの現場で頼られる選択肢になっています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント