
大規模言語モデル(Large Language Model、LLM)は、数十億〜数兆のパラメータを持つTransformerベースのニューラルネットを大量のテキストで事前学習した自然言語処理モデルです。2018年のGPT・BERT登場以降、規模を拡大し続けることで対話・要約・コード生成などあらゆる言語タスクを単一モデルでこなせるようになり、2022年末のChatGPT公開で社会的インパクトが顕在化しました。
この記事の目次
- LLMの中核アイデア
- 代表的なLLM
- LLMを業務で使うときの注意点
- 従来の自然言語処理との違い
- まとめ
LLMの中核アイデア
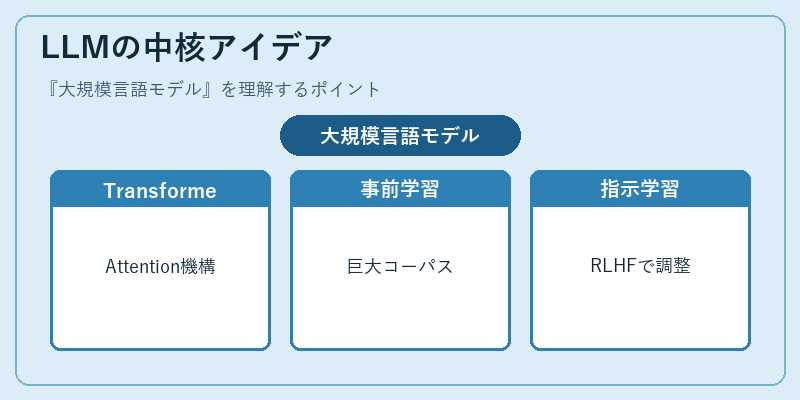
LLMの土台はTransformerと呼ばれるアーキテクチャで、「文中のどの単語に注目すべきか」を学習する自己注意(Self-Attention)機構が肝です。これにより従来のRNNでは難しかった長文の文脈理解と並列計算が両立しました。
事前学習では「次の単語を予測する」というシンプルな目標で大量のテキストを舐めさせ、言語そのものの構造を獲得させます。そのうえで指示追従(Instruction Tuning)と人間からのフィードバックによる強化学習(RLHF)を加えることで、対話で使える形に仕上げる、というのが現代LLMの作り方です。
代表的なLLM

商用LLMはOpenAIのGPT系、AnthropicのClaude、GoogleのGeminiが三巨頭です。対話品質、長文脈対応、コード生成能力、ツール呼び出しなどで競り合っており、数か月単位で順位が入れ替わる激しい競争が続いています。
オープンウェイト勢ではMetaのLlama、フランスのMistral、中国系のQwenやDeepSeekが代表格。自社サーバで動かせる選択肢が増えたことで、「機密データは外に出せない」業務でもLLMを実装できるようになりました。
LLMを業務で使うときの注意点

LLMは万能ではなく、もっともらしい嘘を生成する「ハルシネーション」が避けられない弱点です。事実を確実に答えさせたい用途では、社内文書を検索してから生成させるRAG(Retrieval-Augmented Generation)や、ツール呼び出しによる外部DBとの連携が必須になります。
プロンプト設計(プロンプトエンジニアリング)の重要性は依然として高く、「役割を明示する」「出力形式を指定する」「Few-shot例を入れる」など、細かい工夫で品質が大きく変わります。本番運用では出力監視・コスト管理・プロンプトインジェクション対策まで含めた設計が必要です。
従来の自然言語処理との違い

従来の自然言語処理は「翻訳には翻訳モデル」「分類には分類モデル」とタスクごとに個別のモデルを訓練するのが常識でした。LLMはこれをひっくり返し、ひとつのモデルでプロンプトを変えるだけで多様なタスクをこなせる時代を作りました。
結果として、研究の中心は「タスク特化モデルをどう作るか」から「LLMをどう使いこなすか」「どう小型化するか」「どう正確に答えさせるか」へとシフトしています。業務応用の主戦場もモデル開発からアプリ層・運用層に移り、ITエンジニア全員に関係する技術になりました。
まとめ
LLMはここ数年で最も社会的インパクトの大きいIT技術であり、ChatGPTを使ったことのないエンジニアが珍しい時代になりました。アプリに組み込む側、業務で使う側、いずれも基本的な仕組みを理解しておくことが今後ますます重要になります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント