
Apache Hiveは、Hadoop上でデータウェアハウス機能を提供するオープンソースプロジェクト。2008年にFacebookが開発を開始し、後にApacheソフトウェア財団に移管された。現在では大量の分散データに対してSQL風クエリを用いて迅速な分析を可能にする重要な役割を果たしている。
この記事の目次
- Apache Hiveの概要
- Hiveの起源と発展
- Hiveの内部構造
- Hiveの競合他社との比較
- まとめ
Apache Hiveの概要
Apache Hiveは、データウェアハウス機能を提供するツールであり、データを大量の分散ストレージに格納しつつ、SQL風クエリで簡単に扱えるように設計されている。これにより、Hadoop上で処理を行う際の手間が大幅に軽減される。
しかし、全ての操作がSQLだけで完結するわけではない。例えばUDF(ユーザー定義関数)やCTAS(CREATE TABLE AS SELECT)のような高度な機能を使用することで、より複雑で詳細な分析を可能にする。
Hiveの起源と発展
2008年、HiveはFacebookが内部で利用するために開発を始めた。当初はSQL風の言語とHadoop上で動作するデータウェアハウスツールとして設計された。
その後、Apacheソフトウェア財団に移管され、多くのコミュニティによる貢献を通じて機能や性能が大幅に向上した。現在では、大規模な企業においても重要な役割を果たしている。
Hiveの内部構造
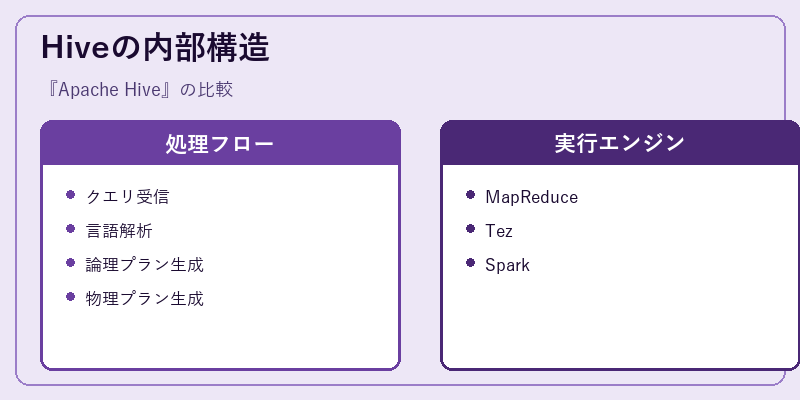
Apache Hiveの処理フローは、まずクエリ受信から始まり、言語解析によってHiveQLが解釈される。次に論理プラン生成と物理プラン生成を行う。
これらのプランはその後、MapReduceやTezといった実行エンジンによって処理され、最終的に結果として返却される。
Hiveの競合他社との比較

Apache Hiveは他のデータウェアハウスや分析ツールと比較して、より高度なSQL機能を提供し、柔軟な実行エンジンを選択可能である。
しかし、競合他社との性能比較では、各実装の最新状況やエコシステムの充実度が大きく影響する。
まとめ
Apache Hiveは、Hadoop上で分散データを容易に管理・分析するために開発された技術であり、現在も継続的な改善と進化を遂げている。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント