
2017年にDatabricksによって開発されたApache Icebergは、大規模な分散システム向けにパフォーマンスとスケーラビリティを提供するためのオープンソースプロジェクトです。この技術はテーブル形式やメタデータストレージを簡潔化し、複数のデータ処理エンジンが同一のデータセットを効率的に共有可能にしました。
この記事の目次
- Apache Icebergの目的
- メタデータ管理
- Icebergの動作原理
- 他のフレームワークとの比較
- まとめ
Apache Icebergの目的
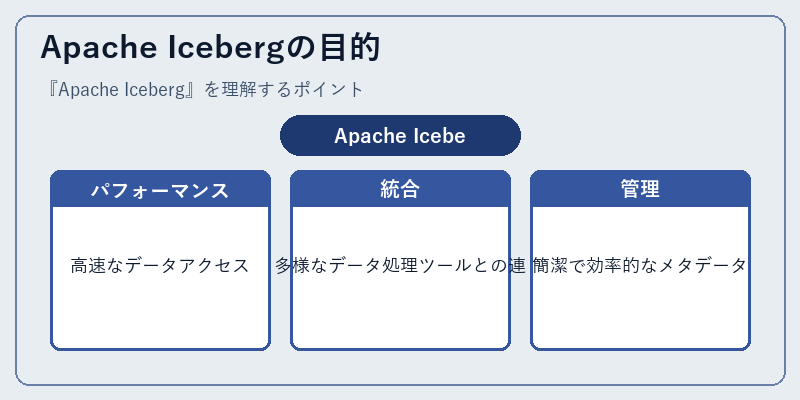
Apache Icebergは、デプロイ時の柔軟性と高パフォーマンスを提供することを目指しています。その特徴の一つとして、HDFSやS3などのストレージバックエンドに対して独立したテーブル形式を持つことが挙げられます。
これにより、Icebergは既存システムに容易に統合可能で、Apache SparkやAmazon Athenaのようなデータ処理ツールとの連携がスムーズになります。
メタデータ管理

Icebergは、メタデータテーブルを利用し、全てのテーブル操作を記録します。これは、データ変更履歴やスキーマ遷移を追跡するために有用です。
また、このフレームワークではコンパクションと呼ばれる処理が行われ、不要なメタデータを削除し、ストレージの使用効率を向上させます。
Icebergの動作原理
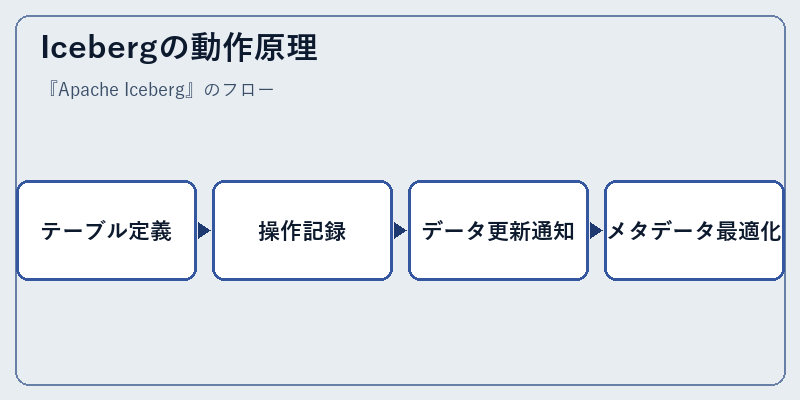
Icebergはまず、テーブルの構造を定義します。これはスキーマの詳細とパーティション戦略によって形成されます。次に、行われた全てのテーブル操作がメタデータテーブル内に記録されます
更新されたデータが存在する場合、Icebergはそれらに対応する新しいファイルアドレスを追加します。その後、不要なメタデータはコンパクション処理によって削除され、システム全体のパフォーマンスと効率が維持されます。
他のフレームワークとの比較
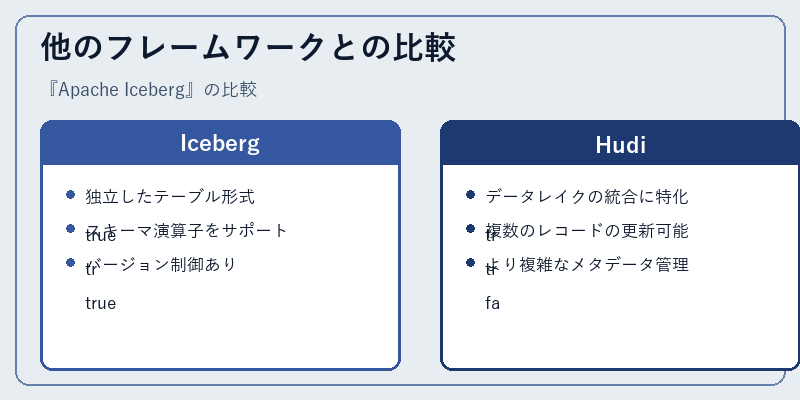
Icebergは、他のプロジェクトとは異なり独自のテーブル形式を持ちます。これにより、あらゆるストレージバックエンドで動作しやすく、異なるエンジン間での一貫性を確保できます
一方、Hudiは更新操作に対応したメカニズムを提供しており、より高度なデータ管理機能を備えていますが、それによって構成やメンテナンスの複雑さも増します。
まとめ
Apache Icebergは、その柔軟性と効率的なメタデータ管理から、大規模データ処理環境において重要な役割を果たすオープンソースフレームワークであることが明らかになりました。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント