
Apache Kafkaは、LinkedInが開発したリアルタイムデータ処理に特化したメッセージングシステムです。現在では、大規模なインフラ構築やマイクロサービスアーキテクチャの実現に欠かせない存在となっています。
この記事の目次
- Apache Kafkaの定義と役割
- Apache Kafkaの仕組みとアーキテクチャ
- Apache Kafkaと他のメッセージングシステムの比較
- Apache Kafkaの展開と利用
- まとめ
Apache Kafkaの定義と役割
Apache Kafkaは、高速なメッセージングとリアルタイムのストリーミング処理を特徴とする。また、メッセージを永続的に保存する機能も持つため、時間系列データの解析にも有用だ。これにより、システム間でデータが効率的かつ信頼性高くやり取りされる。
実際には、Apache Kafkaは多くのウェブサービスやアプリケーションにおいてリアルタイムでのイベント追跡やトランザクション処理に広く使用されています。メッセージを一貫したキューとして管理し、複数のサブスクリプターが同時に同一のメッセージを受け取ることも可能。
Apache Kafkaの仕組みとアーキテクチャ

Apache Kafkaの中心となる概念はパブ/サブモデルで、このモデルによりメッセージが効率的に配信されます。また、データストレージは分散型に設計されているため、高可用性と高い耐障害性を実現しています。
さらに、Apache Kafkaは高度なスケーラビリティを備えており、大量のメッセージ処理に対応します。冗長性も高く、各ノードが故障しても他のノードが自動的に引き継ぐためダウンタイムを最小限に抑えます。
Apache Kafkaと他のメッセージングシステムの比較
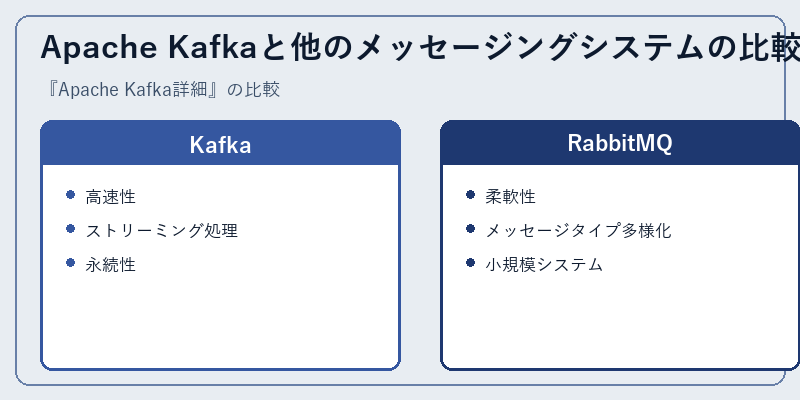
Apache KafkaとRabbitMQを比較すると、Kafkaはメッセージの高速な送受信とストリーミング処理に強く、永続的なデータ保存にも対応しています。これに対し、RabbitMQは柔軟性が高いことが特徴で、様々なタイプのメッセージ処理が可能です。
また、Kafkaは大規模システム向けに設計されているため、パフォーマンスとスケーラビリティが優れている一方、RabbitMQは小規模なシステムや単純なメッセージング要件を満たすのに適しています。
Apache Kafkaの展開と利用

Apache Kafkaを導入するには、まず環境設定から始める必要があり、これにはKafka自体のインストールと必要な依存関係の整備が含まれます。次に、実際のデプロイメントを行い、サービスを起動させます。
その後は、システムのモニタリングも重要なステップとなります。性能データやエラーログなどを定期的にチェックし、必要に応じてスケールアップを行います。このようにしてApache Kafkaは、高度なリアルタイム処理環境を構築する手段として利用されています。
まとめ
Apache Kafkaは、大規模なデータ処理とリアルタイム性の高いシステムで重要な役割を果たしていますが、適切に設定し使いこなすことで、さらなる効率化やパフォーマンス向上を実現することが可能です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント