
Apache Kylinは、アリババが開発したオープンソースのOLAPエンジンです。リアルタイムビッグデータ分析を可能にし、Hadoop上でのパフォーマンス向上に貢献しています。
この記事の目次
- Apache Kylinとは
- Kylinの歴史と開発背景
- Kylinのアーキテクチャ
- Kylinと他のOLAPエンジンの比較
- まとめ
Apache Kylinとは

Apache Kylinは、Hadoop環境上でパワフルなOLAP(オンライン analytical processing)機能を提供するエンジンです。キューブ計算を利用することで、大量のデータから高速に洞察情報を得ることが可能になります。
具体的には、Kylinは高度に並列化されたアルゴリズムを使用して、大量の入力データセットに対して効率的に計算を行い、結果をキャッシュします。これにより、従来よりも遥かに短い応答時間でのクエリ実行が可能になります。
Kylinの歴史と開発背景

Apache Kylinは、アリババが開発したリアルタイムビッグデータ分析エンジンです。アリババグループでは、膨大なデータ量を処理する必要性からKylinを開発しました。
開発初期には主にHadoopエコシステムとの親和性を考慮し、その後はOLAP機能の実装やパフォーマンス改善を進め、2014年3月にApacheプロジェクトとして公開されました。
Kylinのアーキテクチャ
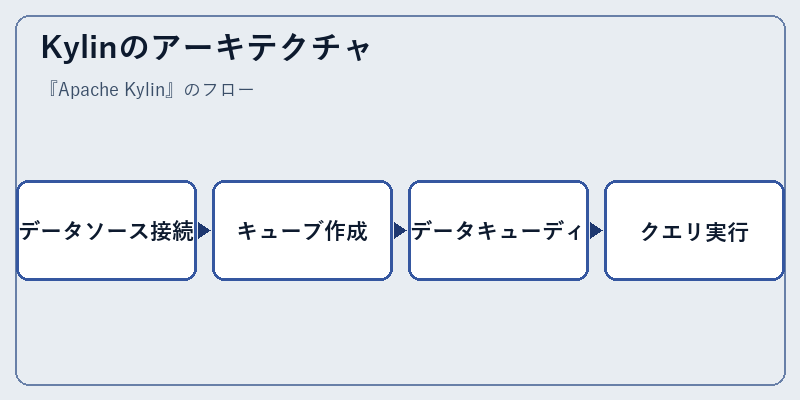
Apache Kylinは、データソースからの取り込み、キューブの生成、結果のキャッシュ化といった一連の工程を効率的に管理します。
具体的には、まずHDFSやKafkaからデータを取り込み、それらをキューブに変換し、最後にクライアントからのリクエストに対して高速な応答を提供します。
Kylinと他のOLAPエンジンの比較

Apache Kylinと他のOLAPエンジンを比較すると、Kylinが持つ独特な特長や優位性が際立つ。
特に、Hadoopに最適化されたアーキテクチャは大規模データ処理の需要に対応し、従来型エンジンでは難しい大量データ対応を可能にします。一方で、従来型のOLAPエンジンは主にオンプレミス環境での運用が想定され、Kylinほど柔軟な拡張性やコスト効率はありません。
まとめ
Apache Kylinはビッグデータ時代におけるOLAP機能強化とパフォーマンス向上のための重要なツールです。Hadoop環境において優れた分析能力を発揮します。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント