
Apache ORCは、Apache Hadoopエコシステムにおいて高速なデータアクセスを実現するための柱となるデータフォーマットです。2013年にデビューし、その後も継続的な改良が行われています。本記事ではORCの基本概念から進化した特性まで、その全貌に迫ります。
この記事の目次
- Apache ORCとは
- ORCの仕組み
- ORCの進化
- ORC vs Parquet
- まとめ
Apache ORCとは
Apache ORCは、Apache Hiveのプロジェクト内で開発が始まりました。元々はHive用に設計されたデータフォーマットでしたが、現在では多くのシステムで採用されています。
ORCの名称は”Optimized Row Columnar”から来ており、その名前の通り行ベースと列ベースの両方のアプローチを統合したフォーマットとなっています。これによりパフォーマンスが向上し、大量のデータに対して効果的なアクセスを可能にしています。
ORCの仕組み

ORCはデータを効率的に管理するための複数の技術を駆使しています。特に、行グループ化とインデックス作成はORCの性能向上に大きく貢献しています。
さらに、ストリーミング読み込み機能により、必要な部分だけを選択的に読むことが可能となっています。これによってI/Oコストの低減とパフォーマンスの向上を同時に実現しています。
ORCの進化
Apache ORCは開発当初から着実に進化を続けています。初版では主にHive向けの機能が中心でしたが、現在では多くのデータ処理ツールで使用される汎用的なフォーマットへと成長しました。
最新バージョンではさらなる性能改善やセキュリティ強化が行われており、今後も継続的に開発が進められることが期待されています。
ORC vs Parquet
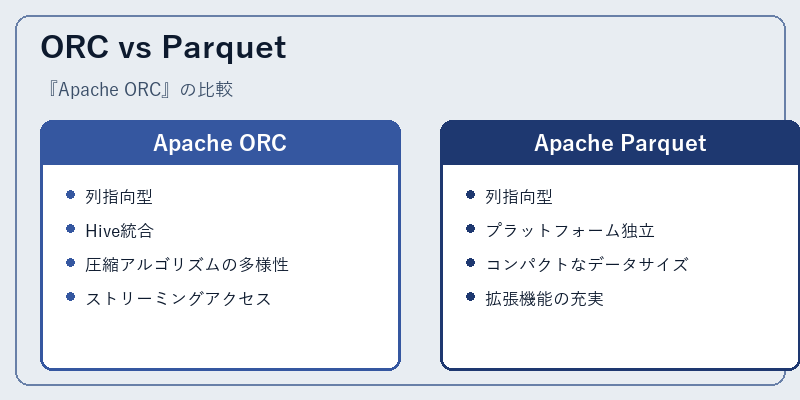
ORCとParquetはどちらも高効率なデータストアフォーマットとして知られています。両者は共に列指向型アプローチを採用し、パフォーマンス向上を追求しています。
一方でORCは主にApache Hadoopエコシステムと深く結びついており、Parquetはより汎用的な設計となっています。また、ORCはストリーミングアクセスが優れているのに対し、Parquetではコンパクトなデータサイズを実現することが特徴です。
まとめ
Apache ORCは、大規模データ処理において重要な役割を果たすフォーマットであるだけでなく、その進化に見る開発者の柔軟性と創造力にも注目が集まるでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント