
DuckDBは、オランダのCWI(情報数学研究所)でMark RaasveldtとHannes Mühleisenが2019年に公開したインプロセス分析データベースです。「SQLiteのOLAP版」というキャッチコピーで知られ、サーバを立てずに単一ファイル・単一プロセスで列指向のSQL分析を完結させます。Parquet/CSV/JSONを直接クエリでき、Pythonと組み合わせたデータ分析の新定番として2022年以降急激に広まりました。
この記事の目次
- DuckDBが「分析向きの組込DB」である理由
- CWIから生まれ、急成長した経緯
- 実務での代表的な使い方
- SQLite・ClickHouse・BigQueryとの比較
- まとめ
DuckDBが「分析向きの組込DB」である理由
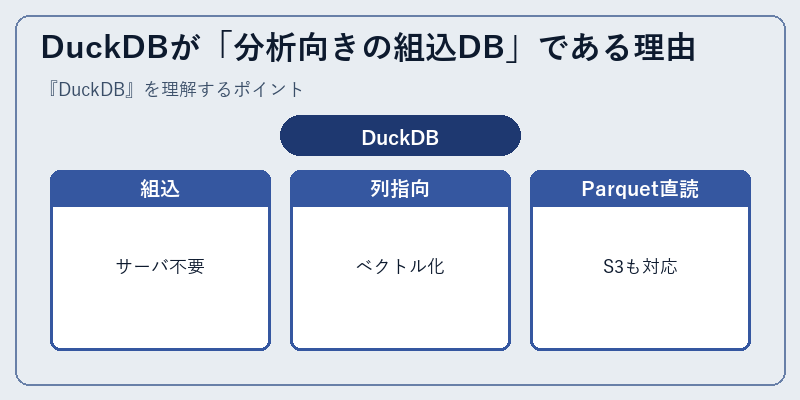
DuckDBはアプリのプロセスにライブラリとして組み込まれて動きます。SQLiteと同じ「サーバを起動しない」哲学のまま、ストレージとクエリエンジンを列指向に置き換えたのが核心です。結果として、ノートPC1台で数億行のParquetを集計するような処理が、Pythonのワンライナーで実現できます。
クエリエンジンはベクトル化実行を採用し、SIMDも積極的に活用します。ストレージは独自フォーマットだけでなく、Parquet・CSV・JSON・Iceberg・Delta Lakeを直接読めるため、データの再配置なしに分析へ進めます。S3上のParquetをLOCALファイルのように扱えるリモートI/Oも標準機能で、データレイク世代に合った設計です。
CWIから生まれ、急成長した経緯

起源は、オランダのCWIで長くデータベース研究を率いてきたPeter Boncz教授周辺の流れにあります。MonetDBで培われた列指向×ベクトル化の知見を、組込み形態で誰でも使える形に再パッケージしたのがDuckDBです。2018年に最初のプロトタイプが論文として発表され、2019年6月に0.1.0が公開されました。
2022年にはDuckDB Foundationが設立され、非営利でのコミュニティ運営と商用のDuckDB Labsの両輪体制が整います。Pythonデータ分析界隈で2022年以降採用が爆発的に増え、2024年6月にようやく長期サポート版の1.0.0が公開されました。MotherDuckというマネージドサービス(2023年公開)も登場し、「組込みのまま、必要に応じてクラウドに伸ばす」モデルが整いつつあります。
実務での代表的な使い方

Pythonの世界では、pandasやPolarsの代替・補完として急速に存在感を増しています。「数GBのCSVをpandasで読むとメモリが足りない」という典型的な悩みを、DuckDBなら数行のSQLで解決できます。Hugging FaceがデータセットビューワにDuckDBを採用しており、ウェブUIから直接Parquetへクエリできる体験を支えています。
ETLの中間処理でも、SparkやAirflowを動かすほどではない規模に対する「ちょうどよい武器」として使われます。BIツール側ではEvidence、Hex、Mode、Rilllなど新世代のSQLファースト製品がDuckDBをローカルエンジンに組み込んでおり、「クラウドDWHにつなぐ前に手元で試す」というワークフローを実現しています。クラウドコストの圧縮にも繋がるため、データチームの注目度は年々高まっています。
SQLite・ClickHouse・BigQueryとの比較

SQLiteとはコンセプトが似ていますが、用途が逆です。SQLiteは小さなトランザクションを次々さばくOLTP向け、DuckDBは大きなテーブルをまとめて集計するOLAP向けで、両方を併用する事例もあります。ClickHouseはサーバ型でクラスタを組む前提のため、「単一マシン分析」が要件ならDuckDBの方が運用が桁違いに楽です。
BigQueryやSnowflakeのようなクラウドDWHとは規模も価格モデルも違います。TBクラスを超え、複数チームが共有する基盤が必要ならクラウドDWH、個人や小チームのアドホック分析・データプロダクトのバックエンドならDuckDBが向く、というのが現状の住み分けです。Polarsとはオーバーラップする部分が大きく、SQLか DataFrame APIかという好みで選ぶケースも増えています。
まとめ
DuckDBは、列指向OLAPを「組込み」という形で誰の手元にも届けた革命的なDBです。クラウドDWHの前段としてもパイプラインの中継地点としても、もはや欠かせない選択肢になっています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント