
Attention機構は機械学習の進歩を牽引し、特にTransformerモデルでの活用が広範囲にわたる。本記事では、その計算量と関連するメモリ使用量の詳細な解明を目指す。
この記事の目次
- Attention機構の定義
- 計算量に関する問題点
- 計算量削減の手法
- Attention機構との比較
- まとめ
Attention機構の定義
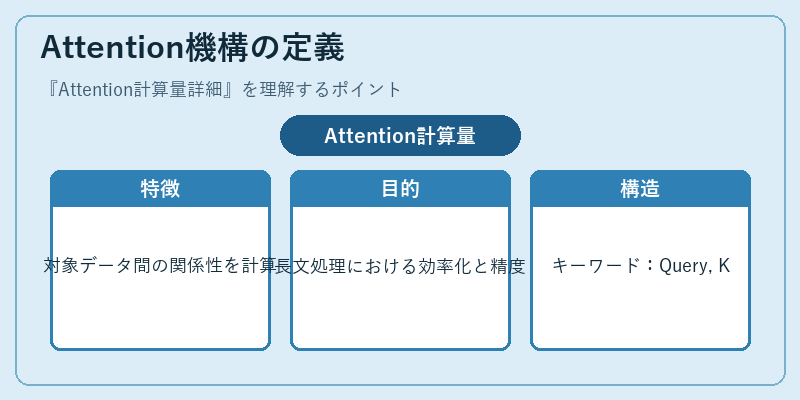
Attention機構は、機械学習モデルが大量の情報から重要な特徴を抽出し、適切な反応を行うために開発された。これは文書内の単語間の関連性を捉えることで、文脈を理解する能力を持つ。
たとえば、翻訳タスクでは、Attention機構は入力文の各単語が目標言語でどの単語に対応するかを識別することで、より自然な翻訳結果を生成します。
計算量に関する問題点

Attention機構は長文処理において計算量が増加し、これによりパフォーマンスや学習時間に悪影響を及ぼす可能性があります。さらに、そのメモリ使用も大きくなるため、大規模なモデルでは制約となります。
このような課題に対応するため、効率的なAttention機構の改良や、異なるアーキテクチャへの移行が検討されています。
計算量削減の手法
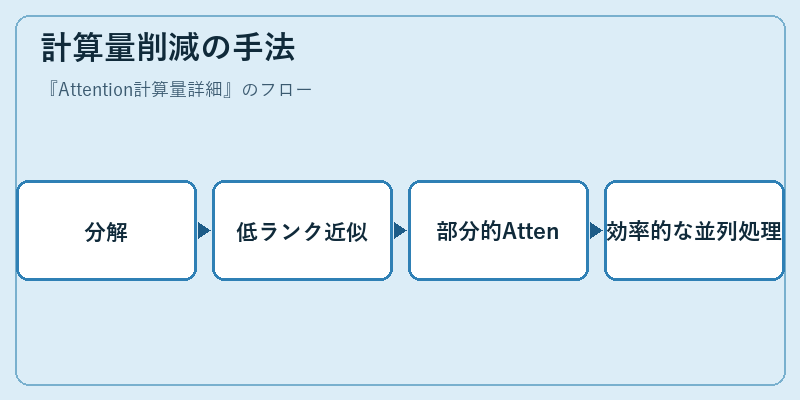
計算量を削減するため、研究者は様々な手法を開発しています。これらの方法は、より少ない計算資源で高い性能を維持することを目指します。
たとえば、部分的Attentionや低ランク近似は、一部の情報しか利用せず、それでも必要な精度を得ることができます。
Attention機構との比較
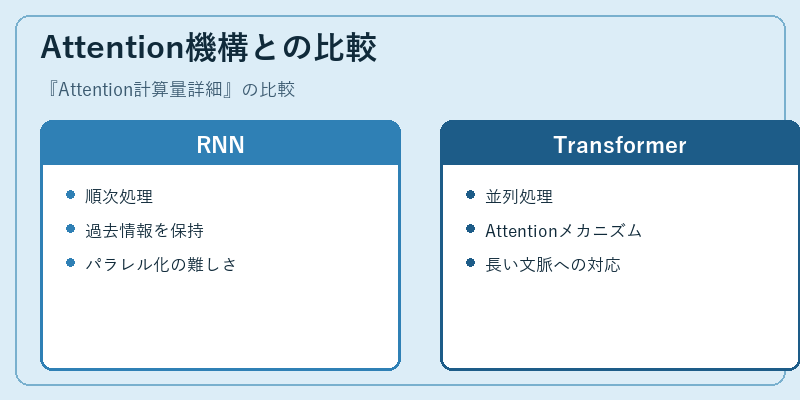
RNNとAttention機構を用いたTransformerモデルは、それぞれ異なるアプローチで長文処理に取り組んでいます。
RNNでは時間のかかる順次処理が必要ですが、Transformerでは並列化が可能であり、より速い学習が可能です。
まとめ
Attention機構の計算量とメモリ使用量は、大規模な文書解析において重要な課題となっています。この記事を通じて、その本質を理解し、効果的な対策を見出すことができるでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント