
袋化(Bootstrap Aggregating, Bagging)は、ランダムフォレストと共に1980年代に誕生した機械学習技術。個々のモデルが過学習しやすい決定木系アルゴリズムを安定させるために考案され、近年では多数の進化的改良を経て、複雑なデータセットにおける予測精度向上に貢献している。
この記事の目次
- Baggingとは何か
- Baggingの歴史と進化
- Baggingの内部仕組み
- Baggingと他のアンサンブル手法の比較
- まとめ
Baggingとは何か
Baggingは、一部の入力データを使用して多くのモデルを作成し、それらの結果を組み合わせることで、より堅牢な予測モデルを構築する技術。
それぞれの子モデルが学習データセットから確率的に抽出されたサブサンプルで訓練され、その結果、各子モデルはオリジナルの入力データとは異なる視点を持つ。
Baggingの歴史と進化

Baggingは、1985年にブーメスタン・ポールとバリー・ウエストがブートストラップ統計手法を用いて提案した。この初期の段階では、単純な決定木を基礎としていた。
その後、ランダムフォレストの導入によりBaggingの強みが増し、モデルの多様性と安定性を高めることで複雑なデータセットでの性能向上に繋がった。
Baggingの内部仕組み
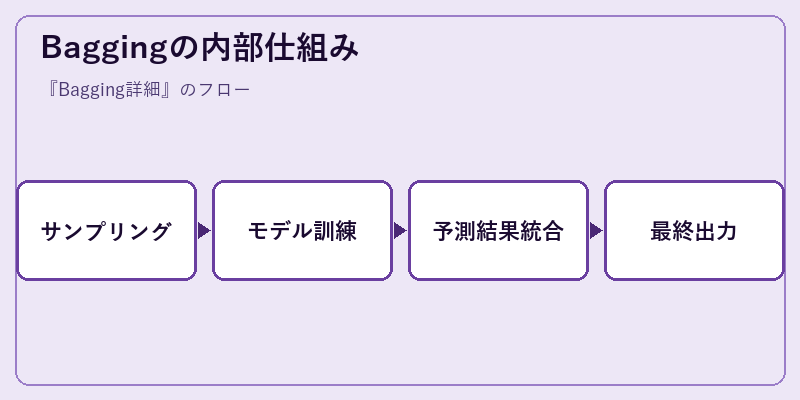
Baggingはまず、入力データセットからブートストラップ法を用いて多数のサンプルを生成。それぞれのサンプルは重複する可能性がある。
次に各サンプルに対して個別のモデル(通常は決定木)を訓練し、その結果に基づき予測を行う。最後に全ての子モデルの予測値が統合され、最終的な推定値が導き出される。
Baggingと他のアンサンブル手法の比較
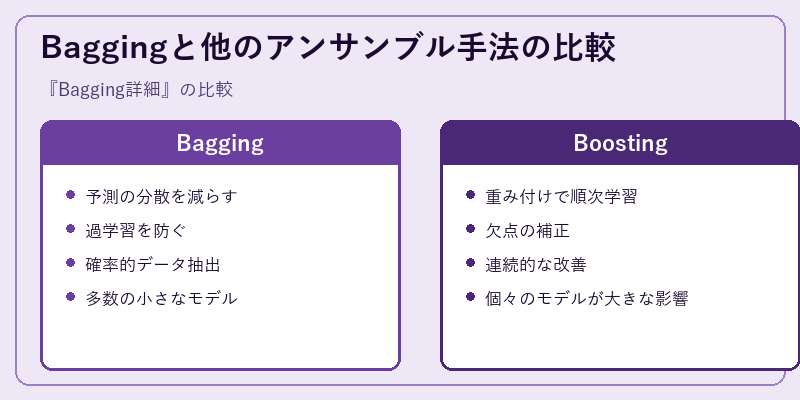
BaggingとBoostingはどちらもアンサンブル学習手法だが、基本的なアプローチには違いがある。Baggingはまず多数の小さなモデルを確率的に抽出して訓練し、それらから平均値や投票に基づく最終予測を生成。
一方、Boostingは重み付けによる個々の誤差修正を行い、その結果全体の性能向上を目指す。このためBaggingが分散を減らすのに対し、Boostingは各モデル間での連携と改善を強調する。
まとめ
Baggingは予測精度と安定性の両立に貢献し、特に非線形データに対する効果が大きい。複雑な問題への適用時にその有用性が際立つ。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント