
2015年に提出されたBatchNormは、深層学習モデルの訓練を高速かつ安定に進める技術として、データサイエンス界隈で大きな注目を集めました。それ以来、さまざまな改良版が提案され、現在でも活用範囲は広がり続けています。
この記事の目次
- BatchNormとは
- BatchNormの歴史
- BatchNormの仕組み
- BatchNormとLayerNormの比較
- まとめ
BatchNormとは
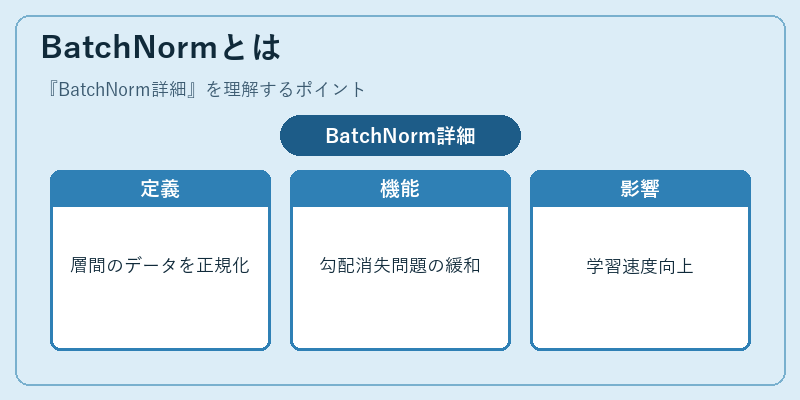
BatchNormは、深層ニューラルネットワークにおいて各層の入力データを正規化する手法です。これにより、重みパラメータが頻繁に更新される際でも、ネットワーク全体の挙動を安定させることが可能となります。
勾配消失や爆発問題といった課題に対処しやすく、モデルがより効率的に学習を行うことをサポートします。
BatchNormの歴史
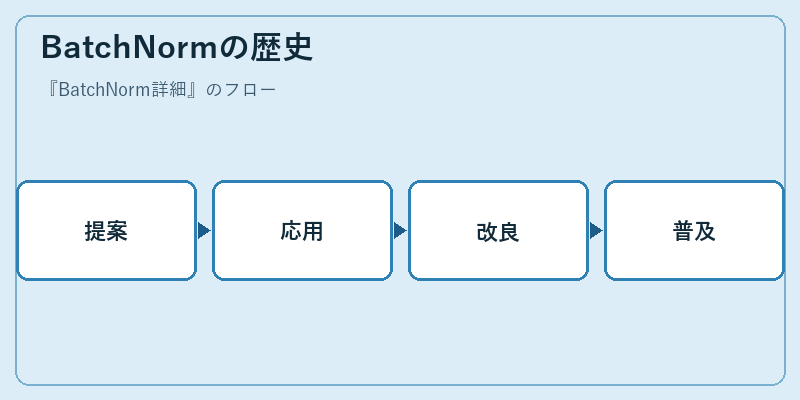
2015年にGoogle Brainチームが提唱したBatchNormは、その導入によって学習プロセスの効率化と安定性を大幅に向上させました。この手法はその後、より深いネットワーク構造に対しても有効であることが実証されました。
様々な改良版が提案され、ResNetやDenseNetなどのアーキテクチャで採用されるなど、機械学習における重要な役割を果たしています。
BatchNormの仕組み

BatchNormは各層の入力を正規化する際、データセット全体ではなく、バッチサイズ分のミニバッチごとに処理を行います。これにより、学習過程におけるパラメータ更新がより安定しやすくなります。
さらに、スケーリングとシフトを適用することで、勾配消失や爆発問題を緩和し、モデルの学習効率を高めます。これらの要素はBatchNormの効果的な機能実現に重要な役割を果たしています。
BatchNormとLayerNormの比較
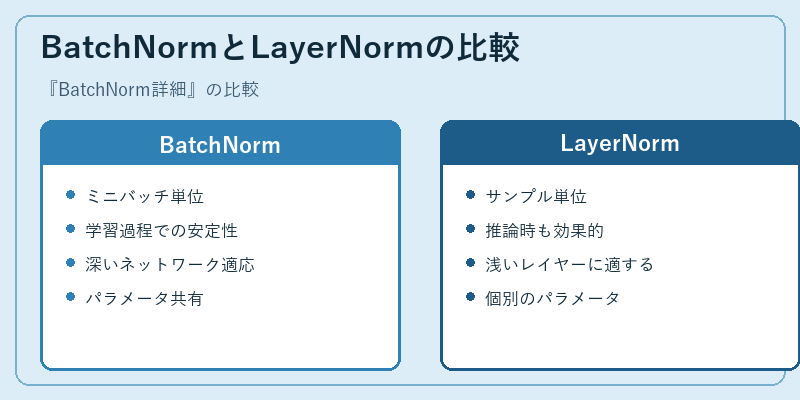
BatchNormと同様な目的を達成するLayerNormは、サンプル毎のデータ処理を行うことで、推論時に安定性が向上します。一方で、より深いネットワークではBatchNormの方が適しています。
これらの違いにより、具体的なシナリオに応じてどちらの手法を選択すべきかを判断する際の基準となり得ます。
まとめ
.BatchNormは機械学習における重要な正規化技術であり、今後も深層学習モデルの性能向上に寄与することが期待されます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント