
2018年にGoogleが発表したBERTは、自然言語処理における事前学習技術として飛躍的な進歩をもたらしました。この記事では、Transformerアーキテクチャに基づくBERT pre-trainingの特徴とその影響について詳しく解説します。
この記事の目次
- Transformerモデルの特徴
- マスク言語モデル(MLM)
- BERT pre-trainingの手順
- BERT vs. BART: 現代の事前学習アプローチ
- まとめ
Transformerモデルの特徴
BERT pre-trainingは、Transformerアーキテクチャの持つ複数の特徴を利用しています。例えば、モデルは強力な表現力を発揮し、大量のデータを効率的に処理できる上に、注意機構により文脈情報を活用します。
具体的には、Transformerは自体が並列化可能な構造を持っているため、高速に学習を行うことができます。また、入力と出力間で直接的な相互作用を持つ「注意メカニズム」を採用しており、この機構がモデルの理解力を向上させます。
マスク言語モデル(MLM)

BERT pre-trainingは、マスク言語モデル(MLM)とnext sentence predictionという2つのタスクで構成されています。MLMでは、一部の単語がランダムにマスキングされ、モデルは残りの文脈からその単語を予測します。
この手法により、BERTは言葉間の関連性や文章全体の意図を理解しやすくなります。つまり、MLMはTransformerモデルにとって不可欠な学習プロセスであり、自然言語処理において非常に強力な結果をもたらすのです。
BERT pre-trainingの手順

BERT pre-trainingは、初期段階で大量のテキストデータを収集し、その上でMLMやNSP(次の文予測)などのタスクに取り組みます。これらのタスクを通じてモデルが十分な汎化能力を持つようになります。
その後、準備したデータを使用してTransformerモデルを訓練し、最終的な微調整と特定のタスクへの応用を行います。このプロセスは各ステップが順次行われるため、全体としては一貫性のある学習過程となります。
BERT vs. BART: 現代の事前学習アプローチ
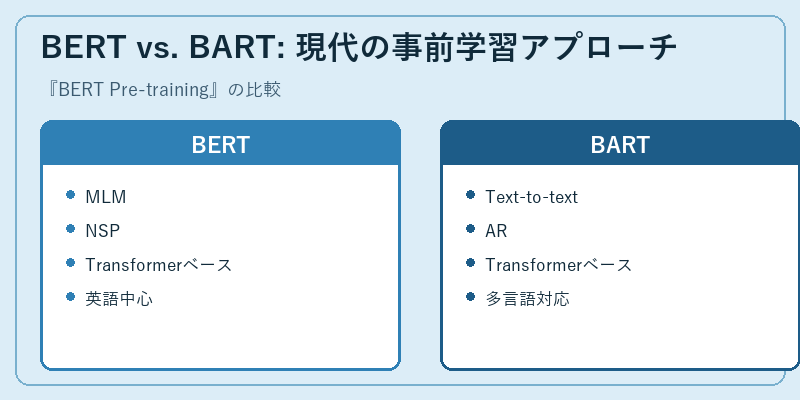
BERT pre-trainingは従来の手法に比べて大きな革新をもたらしましたが、その後登場したBARTというアプローチと比較しても興味深い点があります。
BERTではマスク言語モデルや次文予測タスクが用いられますが、BARTはテキストからテキストへの変換に焦点を当てています。これにより、生成型のタスクに対する性能が向上し、多言語対応にも柔軟に対応できます。
まとめ
BERT pre-trainingは自然言語処理における重要な進歩として位置づけられ、今後の研究開発においてもその影響力は継続するでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント