
Breadth First Search(幅優先探索)は、グラフ理論における重要な探索手法であり、1950年代から使用されてきた。BFSはノードを階層的に調べていくことで、最短経路問題やネットワーク分析などに広く応用されている。本記事ではその原理と実装方法、また他の探索アルゴリズムとの比較について解説する。
この記事の目次
- BFSの基本構造
- BFSの実装例
- BFSの動作フロー
- BFSとDFSとの比較
- まとめ
BFSの基本構造
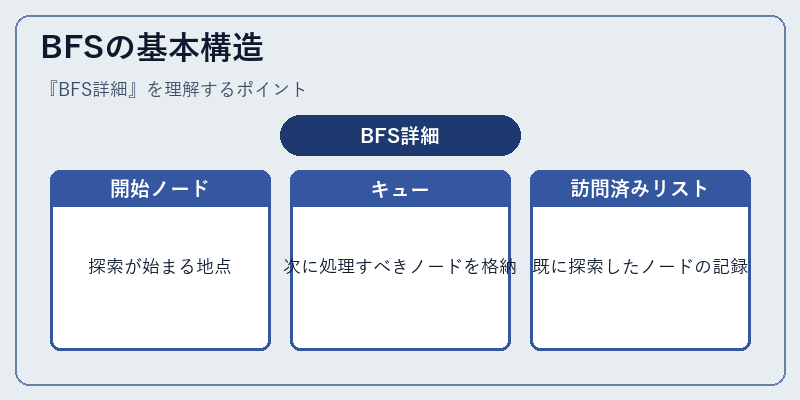
BFSは、グラフ内の全ての隣接ノードを最初に調査し、その後その隣接ノードの隣接ノードへと順次移動する。この過程ではキューを使用して処理の優先度を管理し、既に訪問したノードは記録することで無駄なループを防ぐ。
例えば、ウェブサイト上のページ間のリンク関係をグラフとして捉えると、BFSは最初のページから始まり、そのページに直接リンクされている他のページを一斉に探索する。その後、二つ目のレベルにあるページ群へと移動して調査を続ける。
BFSの実装例

PythonでBFSを実装する際、まず最初に使用するキューと、訪問済みリストを作成する。これらのデータ構造は通常、スタックやリストを使って容易に作れます。
次に、開始ノードから探索を始めるステップを記述し、隣接する全てのノードを処理します。この過程ではそれぞれのノードが訪問済みリストに追加されるため、重複したアクセスは避けることができます。
BFSの動作フロー

BFSの動作は、まず始めに指定した開始ノードから始まります。それ以降、キュー内の最初の要素が処理の対象となり、その隣接する全ての未訪問ノードを次々と新たな調査対象として追加します。
このような反復的なプロセスは通常、特定の終了条件(例えば目標ノードの発見やキューが空になること)によって停止します。
BFSとDFSとの比較
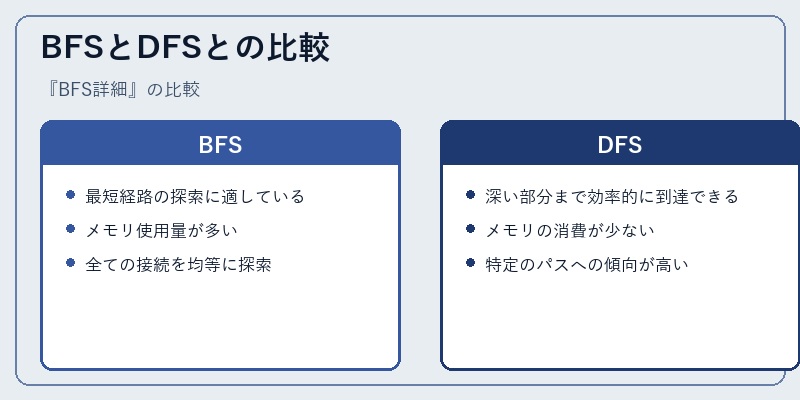
BFSは幅広い探索を行って最も短い経路を見つける一方で、DFSは深さ優先で調べるため、より深い部分に到達しやすいという利点があります。この違いから、それぞれのアルゴリズムが適切な状況を選ぶことが重要です。
例えば、ウェブクローラーにおいてはBFSが好まれることが多い一方、複雑なシステム内のエラートラッキングではDFSの方が有用であることが示されています。
まとめ
幅優先探索(BFS)はグラフの探索アルゴリズムとして広く利用され、その効率性と柔軟性は多様なアプリケーションにおいて価値を提供します。BFSを理解することで、ネットワークやデータベースなどでの最適なパス検出が可能になります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント