
binningは、機械学習やデータサイエンスにおいて重要な概念であり、特に連続値データの取り扱いに焦点を当てます。1980年代から研究されており、近年ではクエリ最適化や統計分析などにも広く利用されています。
目次
この記事の目次
- Binningとは何か
- Binningの歴史的背景
- Binningの種類と適用例
- Binningの長所と短所
- まとめ
Binningとは何か
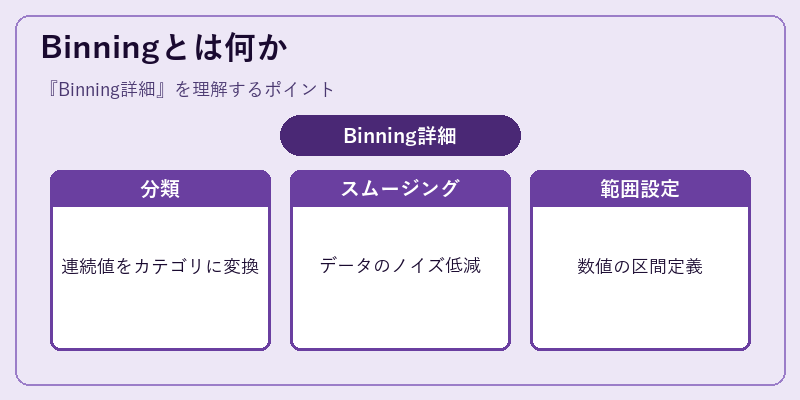
binningは、データ点を一様なサイズまたは特定の特徴に基づいて群(bins)に分けます。これにより複雑な連続分布が管理しやすくなります。
例えば、年齢情報を5歳ごとのグループに分割することで、特定年代層の消費行動分析に役立ちます。
Binningの歴史的背景
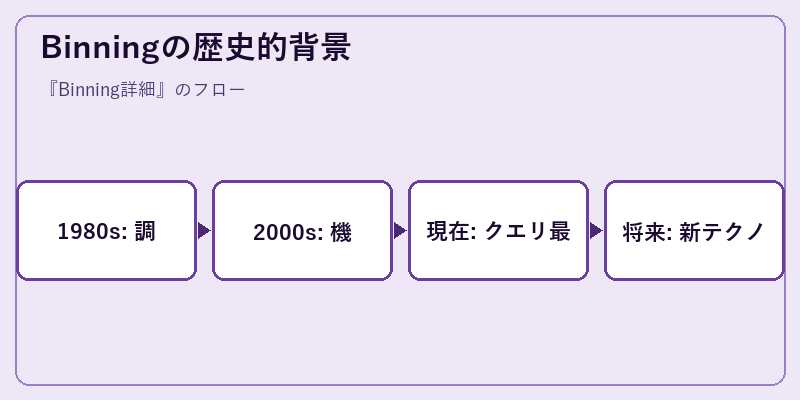
binningは統計分析の手法として、初期は手作業によるデータ整理に使われました。その後、計算機の普及とともに、大量データ処理を可能にしました。
現在では高度なアルゴリズムやソフトウェアで自動化され、大規模なデータセット解析やマシンラーニングでの特徴選択に広く採用されています。
Binningの種類と適用例

等間隔binningは、データ点を固定幅の範囲に分割します。これは簡潔で解釈が容易ですが、分布非対称性への対応が難しい場合があります。
非等間隔方法では、データ内の自然なパターンに合わせて区間を作ります。これにより分析精度が向上することがあります。
Binningの長所と短所

binningは大量の連続値を理解しやすい形にまとめ、解析時間を短縮します。しかし、細かい傾向が欠落する可能性もあるため注意が必要です。
特に金融データや医療記録など個人情報が多く含まれる領域では、適切な範囲設定が求められます。
まとめ
Binningは機械学習や統計解析において重要な技法であり、効率的なデータ理解に寄与します。ただし、データの詳細を損なう可能性もあるため、適用時には慎重な考慮が必要です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント