
DeepSpeedは、Microsoft Researchが2020年2月に公開したPyTorch向けの分散学習・推論最適化ライブラリで、数十億〜数兆パラメータの巨大モデルを限られたGPU資源で訓練できるようにする一連の技術を提供します。中核となるのが「ZeRO」(Zero Redundancy Optimizer)と呼ばれるメモリ最適化で、論文の主著者はサミャム・ラジバンダリ氏らです。GPT-3クラスのモデル学習を念頭に設計されており、BLOOM・MT-NLG 530B・Phi系などの公開LLMはDeepSpeedで学習されました。Hugging Face AccelerateやTransformers Trainerからも呼び出せ、現在もLLMインフラの中核を担っています。
この記事の目次
- ZeROによる三段階のメモリ削減
- 2020年公開から大規模LLMを支える基盤へ
- 巨大モデル学習・推論での主な用途
- FSDP・Megatron-LMとの位置関係
- まとめ
ZeROによる三段階のメモリ削減
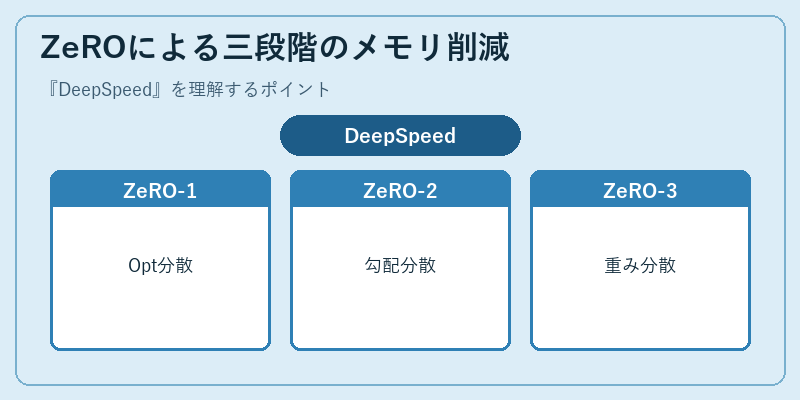
DeepSpeedの代名詞であるZeROは、データ並列学習で各GPUが冗長に保持していたメモリを段階的に分散させる仕組みです。ZeRO-1ではOptimizer状態(Adamの一次・二次モーメント)をGPU間で分割保持し、ZeRO-2では加えて勾配を分割、ZeRO-3では重みパラメータそのものまで分割し、必要なときだけ集約します。段階を上げるほどメモリ消費は減りますが、通信コストとのトレードオフが発生するため、モデルサイズと帯域に応じて選択します。
ZeRO-3に加え、CPU・NVMeへのオフロード(ZeRO-Offload・ZeRO-Infinity)を組み合わせると、GPUメモリに収まらない巨大モデルでもパラメータをCPU・SSDに退避させながら学習できます。サミャム・ラジバンダリ氏らの論文ZeRO(SC20で発表)とZeRO-Infinity(SC21で発表)はベストペーパー候補にもなり、巨大モデル時代の幕開けを技術的に支えた研究として評価されています。
2020年公開から大規模LLMを支える基盤へ

DeepSpeedは2020年2月、Microsoft Researchの分散学習チームによってオープンソースとして公開されました。同月、Turing-NLGという17BパラメータのLLMが当時世界最大として発表され、DeepSpeedがそれを支えた基盤として注目を集めました。その後Microsoftは2021年にNVIDIAと共同でMegatron-Turing NLG 530Bを公開し、DeepSpeedとMegatron-LMの統合(Megatron-DeepSpeed)が数千億パラメータ級モデルの標準的な学習構成として広まりました。
オープンサイエンス連合BigScienceはBLOOM(176B)の学習にMegatron-DeepSpeedを採用し、世界中の研究者がLLM訓練の知見を共有する重要な事例となりました。2023年以降はDeepSpeed-Inference・DeepSpeed-MII・DeepSpeed-Chatなど推論最適化やRLHF向けスタックが追加され、学習だけでなく推論コスト最適化やChatGPT風のRLHFパイプライン構築まで一気通貫で扱える基盤に発展しました。Hugging Face AccelerateとTransformers Trainerからも呼び出せるため、研究室の小規模実験から本番運用まで幅広く採用されています。
巨大モデル学習・推論での主な用途

DeepSpeedの典型用途は、自社で数十億〜数百億パラメータ級のLLMを事前学習するケースです。GPUメモリに乗り切らないモデルをZeRO-3とNVMeオフロードで「物理的に乗らない計算」を可能にし、Megatron-LMとの統合で「データ並列・テンソル並列・パイプライン並列」の3D並列を構成します。BLOOMの学習で使われた構成は、いまも自社LLMを訓練する企業の参照モデルになっています。
推論側ではDeepSpeed-Inferenceがカーネル融合・テンソル並列・KVキャッシュ最適化を提供し、vLLMやTensorRT-LLMが台頭する2024年以降も依然として重要な選択肢です。DeepSpeed-ChatはRLHFパイプライン(SFT→報酬モデル→PPO)をMicrosoftが整理して提供する形で、「自社データでChatGPT風のチャットモデルを作りたい」企業にとって、TRLと並ぶ参照実装になっています。PEFTやAccelerateと組み合わせた省メモリRLHFも可能で、用途の幅は学習・推論・RLHFの全領域に及びます。
FSDP・Megatron-LMとの位置関係

PyTorch標準のFSDP(Fully Sharded Data Parallel)はZeRO-3に相当するメモリ分散を提供し、純正で保守されている点が魅力です。簡単な構成ではFSDPの方が導入しやすく、最近の研究ではFSDPを選ぶケースも増えています。ただし、CPU・NVMeオフロード、ZeRO-Infinityによる超巨大モデル対応、推論最適化スタックなど「広範な最適化を一通り揃えている」という点ではDeepSpeedが優位を保っています。
Megatron-LMはNVIDIA発のテンソル並列・パイプライン並列を含むLLM特化フレームワークで、DeepSpeedとは競合というより「Megatron-LMの並列性 × DeepSpeedのメモリ最適化」という補完関係にあります。推論面ではvLLM・TensorRT-LLMが新興勢力として急速に存在感を増しましたが、学習側のZeRO・3D並列の基盤としては依然としてDeepSpeedが第一に挙がるライブラリで、AccelerateやTransformersの内部実装としても呼び出される位置にあります。
まとめ
DeepSpeedはMicrosoft Researchが2020年に公開した分散学習基盤で、ZeRO最適化を軸に巨大モデル学習を可能にしました。サミャム・ラジバンダリ氏らの研究を実装に落とし込み、Turing-NLG・MT-NLG 530B・BLOOMといった大規模LLMの訓練を支えてきました。学習・推論・RLHFを通じてLLM時代のインフラ中核を担い、AccelerateやTransformersから呼び出される形で現代の生成AI開発を支え続けています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント