Amazon CloudWatchは、AWSが2009年5月に発表したモニタリング・可観測性サービスで、メトリクス・ログ・イベント・アラームを統合的に扱える基盤として発展してきました。EC2のCPU使用率・ALBのリクエスト数・Lambdaの実行時間といった標準メトリクスを自動収集するほか、カスタムメトリクスをPUTで送信したり、アプリログをCloudWatch Logsに転送して保存・検索したりできます。CloudWatch AlarmsはSNS通知・Auto Scalingアクションのトリガーとなり、EventBridge(旧CloudWatch Events)はAWSサービス間の連携イベントを橋渡しします。「AWSで動くシステムの観測の中心」として、ほぼ全てのAWS構成に組み込まれる土台的なサービスです。
この記事の目次
- Metrics・Logs・Events・Alarmsの4本柱
- 2009年公開と進化の歴史
- 運用現場での主な使い方
- Datadog・Prometheusとの位置関係
- まとめ
Metrics・Logs・Events・Alarmsの4本柱
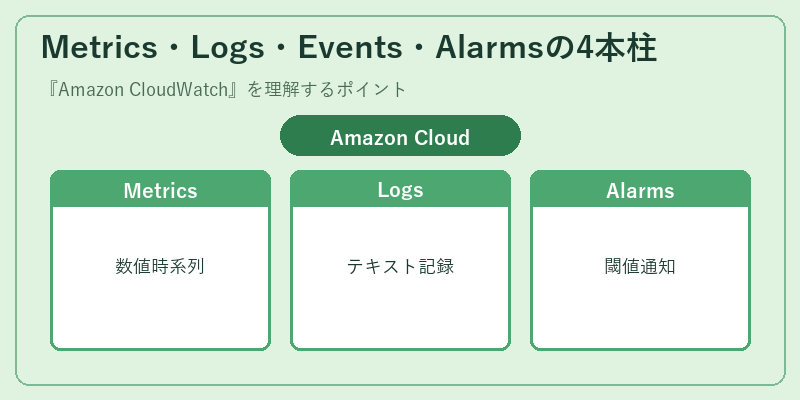
CloudWatchは4つの柱から成り立っています。Metricsは1分または1秒粒度の時系列数値データを扱い、AWS各サービスが自動で発行する標準メトリクスと、ユーザーがPutMetricDataで送るカスタムメトリクスを同じ形式で集約します。Logsはテキストベースのログを保存・検索する仕組みで、ロググループ・ログストリーム・イベントの3階層で構成され、Logs Insightsクエリ言語でJSONログを集計できます。
Alarmsは「あるメトリクスが閾値を◯分連続で超えたら通知/アクション実行」という条件を宣言できる仕組みで、SNS通知やAuto Scalingの起動・停止、Lambdaの呼び出しを連動させます。EventBridge(旧CloudWatch Events)はAWSサービス間で発生するイベント(例:EC2インスタンス停止、CodeDeploy成功)をルール経由でターゲット(Lambda、SQS、Step Functionsなど)に流せる仕組みで、「イベント駆動アーキテクチャ」の中核を担っています。これらが組み合わさることで、観測・通知・自動対応までを一つのサービス上で完結させられます。
2009年公開と進化の歴史

CloudWatchは2009年5月、Amazon EC2の有償アドオン的なサービスとして始まりました。当初はCPU使用率・ディスクI/O・ネットワーク量などの基本メトリクスを5分粒度で収集する程度の機能で、EC2インスタンスの監視に特化していました。Auto Scalingと連動する形でクラウドネイティブな運用を支える基盤として位置付けられていました。
2014年にCloudWatch Logsが追加され、アプリケーションログの集約基盤としての役割が大きくなります。2016年にはCloudWatch Eventsが導入され、AWSサービス間のイベント駆動連携を担うようになり、これは後にEventBridgeとして拡張・改称されました。2018年のContainer Insights、2019年のSynthetics、2020年のContributor InsightsやServiceLensなど、より高度な可観測性機能が次々に追加され、現在はメトリクス・ログ・分散トレース(X-Rayと連携)・RUM(Real User Monitoring)を統合的に扱える「観測プラットフォーム」へと進化しました。
運用現場での主な使い方

ほぼ全てのAWS運用現場でCloudWatchは標準的に使われています。EC2のCPU/メモリ/ディスク、ECSのタスク数、Lambdaのエラー率と実行時間、ALBのリクエスト数とレスポンスタイムなどをCloudWatchダッシュボードに並べ、サービスの健康状態を可視化するのは基本パターンです。アプリログはawslogsエージェントやCloudWatch Agentを経由してLogsに送り、Logs Insightsでfields @timestamp, @message | filter level="ERROR"のようなクエリを叩いて障害解析に使います。
Auto Scalingのトリガーとしての利用も典型で、CloudWatch Alarmが「平均CPU 70%以上が5分継続」を検知するとAuto Scalingが新ノードを起動する、という連動が広く採用されています。EventBridgeルールでS3イベントやCodePipelineの成功をLambdaに流す構成は、サーバレス時代のイベント駆動基盤として一般化しました。RDS・ALB・API Gatewayなどマネージドサービスも標準メトリクスをCloudWatchに自動送信するため、運用ダッシュボードの中心として真っ先に組み込まれます。
Datadog・Prometheusとの位置関係

CloudWatchの強みはAWSサービスとの密結合と、Auto Scaling・EventBridgeとの自然な連動です。AWSに閉じた運用なら追加ツール無しに観測〜自動対応まで完結でき、IAMで権限を一元管理できる点も評価されています。ただし、ダッシュボードのUIや高度な分散トレース、マルチクラウド対応の使い勝手では、DatadogやNew Relicのような専用SaaSの方が洗練されている場面もあります。
オンプレやKubernetes中心の組織では、Prometheus + Grafanaの自前運用が主流で、CloudWatchはAWS資源の観測だけを担当する「片側担当」として位置付けられることもあります。AWSはAmazon Managed Service for Prometheus(AMP)とAmazon Managed Grafana(AMG)を提供しており、Prometheus互換のメトリクスを集める基盤も用意されています。ログ解析の深さではSplunkに譲る場面もありますが、コスト・統合・運用負荷のバランスで、AWS中心のシステムではCloudWatchが第一選択肢として広く採用され続けています。
まとめ
Amazon CloudWatchは2009年提供開始のAWS標準可観測性サービスで、Metrics・Logs・Events・Alarmsの4本柱で構成されます。Auto ScalingやEventBridgeと自然に連携し、観測から自動対応までを一つのサービス上で完結させる土台になっています。Datadog・Prometheusなど他ツールと棲み分けつつも、AWS環境では運用ダッシュボードの中心として真っ先に組み込まれる定番サービスです。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント