
BigQueryはGoogleが2010年5月のGoogle I/Oで一般公開したサーバレス型のデータウェアハウス(DWH)である。もともとは2006年頃から社内で稼働していたアドホック分析エンジン「Dremel」を外部開放したもので、ペタバイト級のテーブルにSQLを投げると数秒〜数十秒で集計が返ってくる挙動が衝撃を持って受け止められた。ノードを事前にプロビジョニングする必要がなく、ストレージとコンピュートが完全に分離されているため、利用者は「クエリを投げて結果を受け取る」ことだけに集中できる。本記事ではDremel譲りの内部構造、課金体系、そしてSnowflakeやRedshiftとの対比までを整理する。
この記事の目次
- Dremelに由来する列指向と分散実行
- オンデマンドと定額の二段構え課金
- ML・地理空間・ストリーミングまで内蔵
- SnowflakeやRedshiftとの位置取り
- まとめ
Dremelに由来する列指向と分散実行
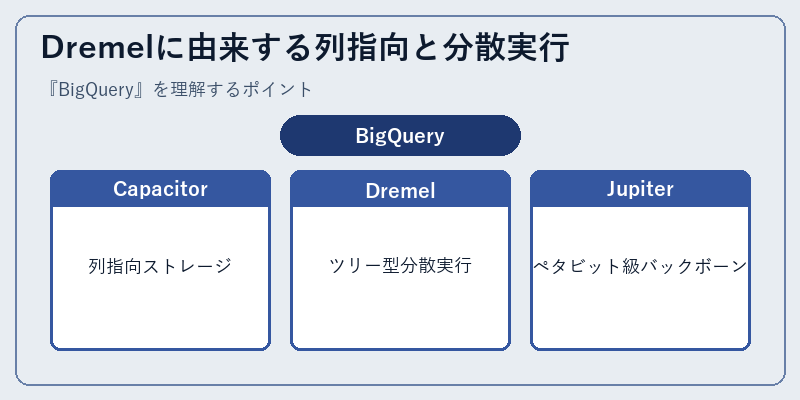
BigQueryのストレージ層は「Capacitor」と呼ばれる独自の列指向フォーマットを採用しており、テーブルはGoogleの分散ファイルシステムColossus上に分散保管される。クエリエンジン「Dremel」はツリー構造で多数のワーカに処理を委譲し、葉ノードが列スキャンと述語評価を担い、中間ノードが部分集計を畳み込み、最後にルートが結果をまとめる。Hadoop系のMapReduceと異なりディスクへの中間書き出しを最小化するため、ペタバイト級のスキャンでも数十秒で完了するケースが珍しくない。
ストレージとコンピュートを結ぶのはGoogleが社内向けに敷設した「Jupiter」ネットワーク基盤で、データセンタ内をペタビット級の帯域で結ぶ。これによりコンピュートノードがどのストレージブロックに当たってもネットワークがボトルネックになりにくく、結果として「テーブルをコピーせずに直接スキャンする」設計が成立している。他社DWHが採用しがちな「ノードにデータを張り付けるシェアードナッシング」とは思想が異なる点が特徴的だ。
オンデマンドと定額の二段構え課金

BigQueryの課金は「スキャンしたバイト量に応じる従量課金(オンデマンド)」と「スロットと呼ばれる計算ユニットを時間単位で確保するEditions」の二段構えになっている。2023年のリブランディングでStandard、Enterprise、Enterprise Plusという3階層のEditionsが導入され、ワークロード単位で性能とセキュリティ機能を選べるようになった。アドホック分析が中心の組織はオンデマンド、定常的な大規模バッチを抱える組織はEditions、と使い分ける構成が一般的である。
ストレージ側は「アクティブ」と「長期」の二段料金で、90日間更新されないテーブルは自動的に長期料金に落ちる仕組みがある。「クエリを投げない限り計算課金はゼロ」「ストレージは寝かせると半額」という性質は、データレイク的にとりあえず貯めておきたい組織にとって心理的ハードルを下げる要素となっている。一方で大量SELECT *を癖で打つチームでは想定外の課金が起きやすく、パーティション設計と列の絞り込みは引き続き重要だ。
ML・地理空間・ストリーミングまで内蔵

BigQueryはピュアなDWHにとどまらず、CREATE MODEL文で線形回帰やARIMA、ブースティング木などを学習できる「BigQuery ML」、緯度経度の関数群を備える「BigQuery GIS」を内蔵している。データを外部ツールにエクスポートせずSQLだけで予測モデルや距離計算を回せるため、データサイエンティストがいないチームでも基礎的な分析を完結できる。近年はベクトル検索関数も追加され、生成AI連携の入口としても使えるようになってきた。
ストリーミング側では従来の「streaming insert」に代わって「Storage Write API」が標準となり、低遅延かつ厳密に一回の取り込みが可能になった。BIツールからの応答性能を底上げする「BI Engine」、AWS S3やAzure Blobに置いたデータをBigQueryのSQLでそのまま問い合わせる「BigQuery Omni」も揃い、マルチクラウド戦略の中心に据える企業が増えている。結果としてBigQueryは単なるDWHから「分析データ基盤のハブ」へと役割を広げている。
SnowflakeやRedshiftとの位置取り
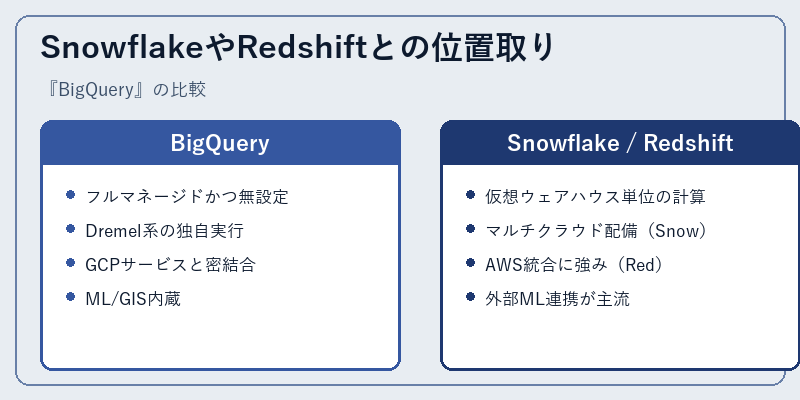
クラウドDWH市場ではAWSのRedshift、独立系のSnowflakeとの三つ巴が続いている。Redshiftはノード型から始まり、現在は「Redshift Serverless」も提供されるがAWSエコシステムとの結合が出発点だ。Snowflakeは仮想ウェアハウス単位で計算リソースをスケールし、AWS・Azure・GCPの3クラウドに同等展開できるマルチクラウド志向が強みである。
対するBigQueryは「ノードという概念を表に出さない」設計を徹底し、スロットという内部単位以外をユーザーに意識させない。GoogleアナリティクスやFirebase、Vertex AIといった周辺サービスとのワンクリック連携は他社では真似しづらく、Webサービスや広告系企業との親和性が際立つ。選定時はチームのクラウド資産、リアルタイム性要件、ML活用度合いを軸に比較すると判断しやすい。
まとめ
BigQueryはDremelの内部技術を外部公開する形で2010年に登場し、サーバレスDWHというカテゴリーを牽引してきた。列指向ストレージ、ツリー型分散実行、ペタビット級ネットワークという三本柱に、ML・GIS・ストリーミング・マルチクラウドが積み上がり、今や「分析基盤のハブ」と呼べる存在へ成長している。クエリの軽さに甘えず、スキャン範囲とパーティション設計を意識すれば、コストとパフォーマンスを両立できる頼れるDWHだと言える。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント