
Claude Safety Guardrailsは、Anthropicが開発した人工知能アシスタントClaudeを安全かつ有用なツールにするための規制メカニズムです。この記事では、その機能と意義について詳しく解説します。
この記事の目次
- Claude Safety Guardrailsとは
- Guardrailsの機能と仕組み
- Guardrailsとの比較
- Guardrailsの適用と展望
- まとめ
Claude Safety Guardrailsとは
人工知能の進化に伴い、AIアシスタントが社会や個人に対して不適切な行動を取る可能性があります。その課題に対処するため、AnthropicはClaude Safety Guardrailsを開発しました。
このフレームワークは、ユーザーの要求に対する応答を制御し、倫理的・法的な問題を回避します。また、不適切なコンテンツ生成や個人情報漏洩防止にも寄与しています。
Guardrailsの機能と仕組み
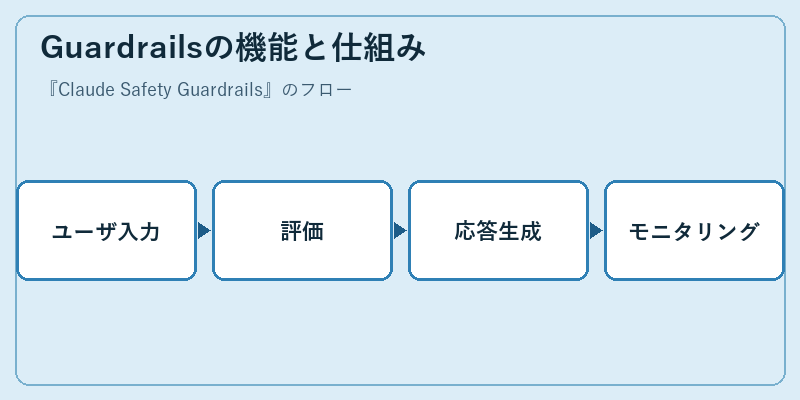
Claude Safety Guardrailsは、複数段階の処理を経て機能します。まずユーザーからの入力を受けて、その内容が安全な範囲内かどうか評価します。
その後、適切な応答を生成し、常にアシスタントの行動をモニタリングすることで潜在的なリスクを抑制しています。これらのプロセスは継続的に改善され続けています。
Guardrailsとの比較

Claude Safety Guardrailsは、同社の他の人工知能とは一線を画す独自性を持っています。他社製品と比較すると、安全面やユーザー設定の柔軟性で優位に立っています。
一方、競合するAIアシスタントではこれらの機能が欠けている場合が多く、安全性や応答品質において劣る可能性があります。Claude Safety Guardrailsはその課題を解決しようとします。
Guardrailsの適用と展望

Claude Safety Guardrailsは、AIアシスタントの開発初期から運用まで幅広く適用可能です。また、その効果をより引き出すために定期的な改良や更新が行われます。
さらに、ユーザーに対する教育と適切な統合テストを通じて、Guardrails機能を最大限に活用することが推奨されています。これらの取り組みにより、AIアシスタントの信頼性が向上するでしょう。
まとめ
Claude Safety Guardrailsは、人工知能アシスタントにおける倫理と安全性を維持し、ユーザーに安心感を与える重要な役割を果たしています。今後の発展にも注目していきたいところです。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント