
Lisp系言語であるClojureでは、特別なデータ型や表現法が用意されており、これらはプログラムの効率性と簡潔さを大幅に向上させる。この記事では、Clojureにおけるデータ構造の特徴や歴史的背景について紹介する。
この記事の目次
- Clojureデータ構造の定義
- Clojureデータ構造の歴史
- Clojureデータ構造の仕組み
- Clojureデータ構造と他の言語の比較
- まとめ
Clojureデータ構造の定義
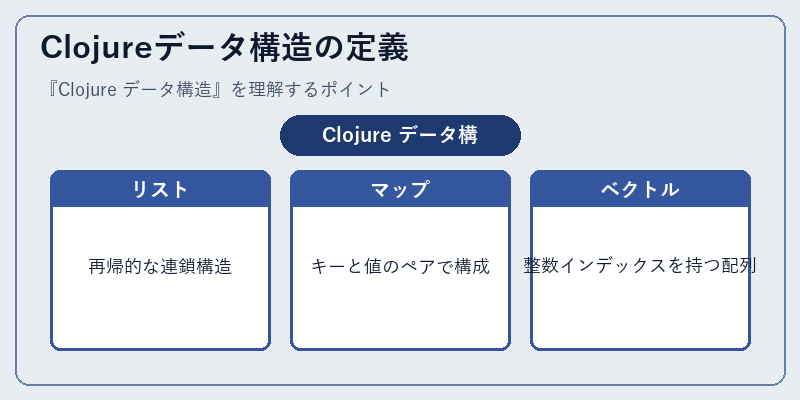
Clojureでは、主にリスト、マップ、ベクトルが基本となるデータ構造として利用される。これらはLisp言語から引き継いだものであるとともに、機能性を高めるために改良が加えられている。
たとえば、リストは再帰的な連鎖構造であり、要素の追加や削除が容易に行える。一方でマップはキーと値のペアから成るため、検索操作も高速である。
Clojureデータ構造の歴史

Clojureのデータ構造は、1958年にStanford大学で開発されたLispから始まった。当初のリストは単純なセル構造だったが、後にSchemeやCommon Lispといった他のLisp系言語ではより複雑な構造に進化した。
Clojureは2007年にStuart Hallowayによって開発され、これらの要素を統合しつつ現代的な要件に対応するように改良されている。
Clojureデータ構造の仕組み
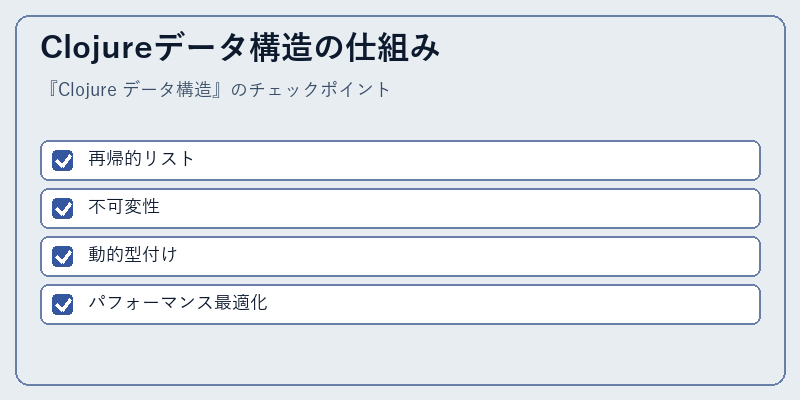
Clojureでは、データ構造が不可変であり、再帰的なリストや配列の操作を可能にする。この特性は並行処理における安全性と効率性に貢献している。
加えて、動的型付けにより柔軟な型処理が可能で、パフォーマンス最適化のために様々な手順が用意されている。
Clojureデータ構造と他の言語の比較

Javaのような言語と比べて、Clojureはデータ構造の不可変性を強調し、より簡潔で効率的なコードを作成できる。静的型付けとは対照的に、動的型付けにより柔軟な型処理が可能になる。
また、Javaではリストアダプタを使用するのに対し、Clojureでは関数型APIを通じてデータ構造を操作することが一般的である。
まとめ
Clojureのデータ構造は、その柔軟性とパフォーマンスから、現代的なソフトウェア開発において大きな役割を果たしている。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント