
Apache Solrは2004年にCNETのYonik Seeleyによって開発が始まった、Apache Lucene上に構築された分散検索プラットフォームです。2006年にApache Software Foundationへ寄贈され、2010年にはLuceneとSolrが同一プロジェクトに統合されました(その後2021年に再び分離)。REST APIによる検索操作、ファセット、ハイライト、Spellcheck、SolrCloudモードでの分散運用、Schema APIによるスキーマ管理など、エンタープライズ検索に必要な機能を網羅的に提供しています。Elasticsearchの登場以前は事実上の全文検索の標準であり、現在もApple、Bloomberg、Ticketmaster、Wikimedia財団など多数の大規模システムで本番採用されています。
この記事の目次
- CNET発のオープンソース化と歴史
- アーキテクチャと主要機能
- Solrが選ばれ続ける現場の特徴
- ElasticsearchやOpenSearchとの違い
- まとめ
CNET発のオープンソース化と歴史

Solrは2004年、CNET Networks社内でYonik Seeley氏が同社のWebサイト検索基盤として開発したことに端を発します。Apache Luceneの薄いラッパーから始まったプロジェクトでしたが、HTTPを介して検索リクエストを受けるサーバとしての側面を強化し、ファセット集計やキャッシュ機構など独自機能を追加していきました。2006年1月にCNETがコードをApache Software Foundationへ寄贈し、Lucene PMCの傘下サブプロジェクトとして公開されたのがOSS Solrの始まりです。
2010年にはLucene本体とSolrのコードリポジトリが統合され、同一バージョン番号で一緒にリリースされる体制が10年以上続きました。しかし2021年にSolrは再びLuceneから分離し、独立したApache Solrプロジェクトとして発展する道を選びます。再分離後はリリースサイクルを独自に設定でき、機能追加のスピード感を取り戻したと評価されています。Yonik Seeley氏は2020年代にOpenSearchプロジェクトにも関わりつつ、検索エンジンOSS界の重鎮として活動を続けています。
アーキテクチャと主要機能
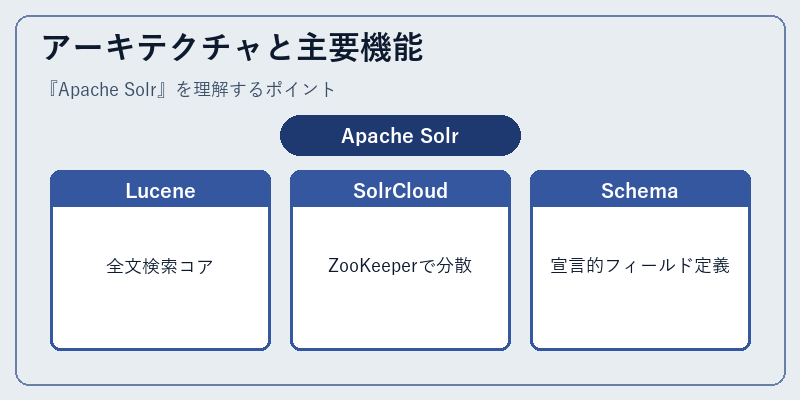
Solrの中核はApache Luceneライブラリですが、その上にWebアプリケーションとしての検索サーバ機能、設定管理、運用ツールを構築している点に特徴があります。ドキュメントの追加・更新・削除はHTTP/RESTで行え、検索もURLクエリパラメータ経由のシンプルなインターフェースで実行できます。ファセット、ハイライト、Spellcheck、Suggester、More Like This、Geospatial検索、Pivot Facet、Stats Facetなど、エンタープライズ検索で必要となる機能群が標準同梱されている点が他の選択肢との大きな違いです。
SolrCloudモードを有効にすると、Apache ZooKeeperを通じて複数ノード間でクラスタ状態を共有し、シャーディングとレプリケーションを自動管理する分散検索クラスタとして動作します。Schema APIによるスキーマ定義、Config APIによる設定変更がREST経由で動的に行え、運用中のサービスを停止せずにフィールド追加や検索ロジックの変更が可能です。認証はBasic、Kerberos、JWT、PKIなど多様な方式に対応し、エンタープライズの監査要件にも耐える設計が長年磨かれてきました。
Solrが選ばれ続ける現場の特徴

Solrが特に強い領域は、検索品質の細かな調整と検索結果の説明責任が求められるエンタープライズ用途です。BlacklightやVuFindといった図書館蔵書検索基盤の標準バックエンドとして長年採用され、世界中の大学図書館や公共図書館で稼働しています。ECサイトの商品検索、新聞社の記事横断検索、政府機関の文書検索、HRシステムの履歴書検索など、検索ロジックの透明性と長期運用の安定性が重視される領域で根強い人気を保っています。
Elasticsearchが「ログ分析と観測性に強い」というポジションを獲得して以降、Solrは「真の検索ユースケース」に集中する形で住み分けが進みました。Function Queryによる柔軟なスコアリング、edismaxパーサ、Result Groupingなど、検索品質を細かく制御するための機能が豊富で、辞書ファイルベースのシノニム管理やストップワード管理は今でも検索エンジニアにとって扱いやすいインターフェースです。Wikimedia財団はWikipediaの検索基盤にElasticsearchを採用していますが、それでもSolrを採用する大規模Webサービスは依然として多く、知名度の差ほど採用シェアに大きな開きがあるわけではないのが実情です。
ElasticsearchやOpenSearchとの違い

Solrは「スキーマを明示的に定義してから検索する」という伝統的なRDB寄りのアプローチを取るのに対し、Elasticsearch/OpenSearchは「ドキュメントを投げ込めば動的にマッピングが作られる」というスキーマレス志向です。この設計思想の違いは現在も色濃く残っており、Solrは厳密なスキーマ管理が求められる図書館・公的機関で好まれ、Elastic系はログ分析や試行錯誤の多いアプリケーション開発で好まれる傾向があります。クラスタ管理もSolrはZooKeeper必須、Elastic系は内部にRaftベースの合意機構を持つという違いがあります。
ベクトル検索のサポートはどちらも追加されていますが、Elastic系の方がMLパイプラインとの統合が一歩進んでいる一方、Solrも9.0以降でDense Vectorフィールドを正式サポートし、knn検索が標準機能になっています。観測性プラットフォームとしての存在感ではElasticsearch/OpenSearchに圧倒される一方、純粋な「検索エンジン」としての成熟度と柔軟性ではSolrが依然として強い選択肢であり続けています。新規採用の事例数では確かに減っているものの、既存採用の継続率は極めて高く、「Solrを置き換える理由が見当たらない」という評価が現場でも一般的です。
まとめ
Apache Solrは20年にわたってLuceneと共に進化してきたエンタープライズ検索の代表格で、図書館・EC・政府機関など検索品質と長期安定性が問われる現場で確固たる地位を維持しています。Elasticsearchの台頭以降は新規採用のシェアこそ縮小しましたが、その分検索本来のユースケースに集中する形で進化を続け、SolrCloudやDense Vectorといった現代的な機能を取り込みながら老舗の風格を保っています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント