
Cohere Embeddingsは、人間言語を機械が理解しやすい形式に変換する技術です。その背景や開発者、主要な特徴と役割について詳しく紹介します。
この記事の目次
- Cohere Embeddingsとは
- 変換原理
- 実際の利用例
- 他の埋め込み技術との比較
- まとめ
Cohere Embeddingsとは
Cohere Embeddingsは、自然言語処理技術の一つとして、テキストを数値ベクトルに変換します。これにより、機械学習モデルが文脈や意味関係を理解する能力が向上します。このプロセスは大規模な学習データセットを通じて精度を高めます。
具体的には、Wikipediaやニュース記事などから得られる大量のテキストデータを使ってトレーニングを行い、効果的なベクトル表現を生成します。結果として、類似文書検索や自動要約などのタスクで優れたパフォーマンスが可能になります。
変換原理

Cohere Embeddingsの基本的な操作は、入力されたテキストを適切な数値ベクトルに変換することです。この過程で使用される数学的手法が主には正規化と特徴抽出技術に基づいています。
具体的には、各単語または短文を高次元空間上の点として表現し、それらの位置関係から意味的な類似性や対立関係を推測します。このプロセスにより、異なる文章でも内容が近いもの同士はベクトル空間上で接近するといった特性が得られます。
実際の利用例

Cohere Embeddingsは、テキストデータの解析や活用に広く利用されています。例えば、ウェブ記事の類似性を測定したり、大量の顧客レビューから傾向を見つけ出すといった用途があります。
また、ニュース記事の要約作成やユーザーが発信した投稿に対する反応分析なども可能とします。さらに、製品のパーソナライズレコメンデーションやチャットボットによる自然な対話生成などでも効果を発揮しています。
他の埋め込み技術との比較
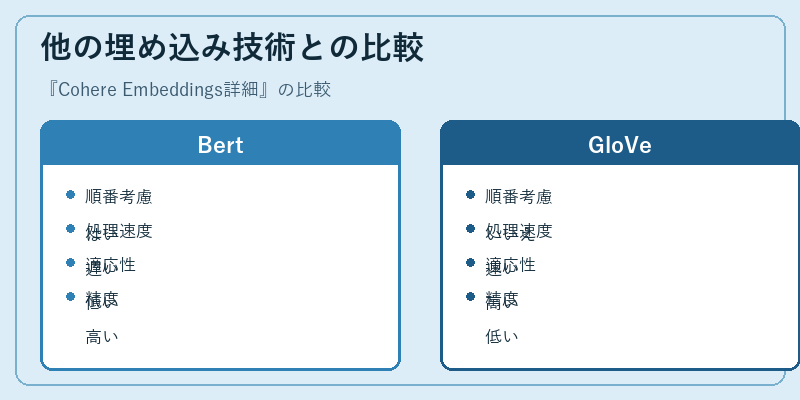
Cohere Embeddingsは、テキストデータを処理する他の主要な埋め込み技術と比較して特徴があります。例えばBertと比べると、文脈の順序に敏感であるため精度が高いですが、一方で計算資源が必要です。
対照的にGloVeでは単語の上下関係は考慮されませんが、処理速度が速く、新しいデータへの適応性があります。これらを踏まえつつ、具体的なニーズに最適な埋め込み技術を選択することが重要です。
まとめ
Cohere Embeddingsの活用により、大量かつ多様なテキストデータから有用な洞察を得ることが可能になります。今後も新たな研究や開発によって機能が進化していくことが期待されます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント