
Apache LuceneはDoug Cutting氏が1999年に開発を始めた、Java製のオープンソース全文検索ライブラリです。検索エンジンそのものではなく「検索エンジンを作るためのライブラリ」であり、Apache Solr、Elasticsearch、OpenSearch、Nutch、CrateDBなど現代の主要な検索プロダクトのほぼ全てがLuceneを基盤として構築されています。転置インデックス、BM25スコアリング、形態素解析、ファセット、Spellcheck、ベクトル検索など、検索に必要なアルゴリズムとデータ構造を高品質に提供しており、JVMエコシステムにおける検索の事実上の標準として君臨してきました。Doug Cutting氏はその後Hadoopプロジェクトを立ち上げた人物としても知られており、Luceneと共にビッグデータ・検索の世界に多大な影響を与えました。
この記事の目次
- 1999年Doug Cuttingの個人開発から始まる歴史
- Luceneの内部構造と主要アルゴリズム
- Luceneを基盤に持つ主要プロダクト
- ライブラリと検索サーバの位置付け
- まとめ
1999年Doug Cuttingの個人開発から始まる歴史

Luceneは1999年、Doug Cutting氏が個人プロジェクトとして開発を始めた検索ライブラリです。彼はそれ以前にXeroxの研究機関やApple、Exciteなどで検索エンジン関連の業務に携わっており、その経験を活かして「誰でも検索エンジンを作れるライブラリ」を目指してJavaで実装を進めました。名前は妻のミドルネーム「Lucene」に由来するという逸話が知られています。公開当初はSourceForgeで配布されていましたが、2001年9月にApache Software Foundationのトップレベルプロジェクトとして寄贈されました。
2005年にはLuceneのサブプロジェクトとしてNutch(ウェブクロウラ)とSolrが加わり、Luceneプロジェクト群として広がっていきました。2010年にLuceneとSolrは同じリポジトリで開発される統合体制となり、Doug Cuttingは別途Hadoopプロジェクトを立ち上げてビッグデータ時代の礎を築いていきます。Luceneは2021年にSolrから分離して独立プロジェクトに戻り、現在はLucene 9.x系と2024年10月公開のLucene 10系が並行して保守されています。リリースペースは安定しており、四半世紀にわたって積み重ねられた最適化と機能拡張が、現代の検索エンジン群を支える礎になっています。
Luceneの内部構造と主要アルゴリズム

Luceneのインデックスは「Segment」と呼ばれる複数の不変ファイル群で構成されており、新規ドキュメントは新しいSegmentとして書き込まれ、削除はDeletion Vectorで記録されます。Segmentは定期的にマージされて統合されるため、書き込み性能と検索性能を両立できる構造になっています。転置インデックスは語彙辞書(Term Dictionary)と位置情報リスト(Posting List)から成り、近年はFST(Finite State Transducer)を使った圧縮、Postings形式のブロック圧縮など継続的にアルゴリズム改善が積み重ねられています。
スコアリングはLucene 6(2016年)からデフォルトがBM25に切り替わりました(それ以前はTF-IDF系のVector Space Modelが標準)。BM25のk1とbパラメータはフィールド単位で調整可能で、検索品質の細やかな制御が可能です。また、AnalyzerはTokenizer、CharFilter、TokenFilterの組み合わせで構成され、形態素解析(Kuromoji、ICU、Sudachi連携)、N-gram、Stemming、Lowercasing、Stopwords除去などを柔軟に組めます。Lucene 9.x系からはDense Vectorフィールドが追加され、HNSWアルゴリズムによる近似最近傍検索がコアに組み込まれました。BM25とベクトルの両方を一つのライブラリでハンドリングできる点が、現代のRAG時代における重要な強みになっています。
Luceneを基盤に持つ主要プロダクト

Luceneは「検索エンジンライブラリ」であって、検索サーバとして直接利用されることは少ないものの、Java/JVMエコシステムで「検索といえばLucene」というポジションを確立しています。Apache Solr、Elasticsearch、OpenSearchはいずれもLuceneを内部に取り込んだ検索サーバ製品で、これら3つだけで全文検索エンジン市場の大半を占めると言っても過言ではありません。Apache NutchはLuceneと同じくCuttingが立ち上げたWebクロウラで、収集したコンテンツをLuceneインデックスに格納する構成を取ります。
それ以外にもCrateDB、Neo4jの全文検索機能、HibernateのSearch機能(Hibernate Search)、CompassやElasticsuiteなど、Luceneを利用するJVMベースのプロダクトは枚挙にいとまがありません。C++移植版のLucene++、.NET移植のLucene.NET、Python移植のPyLuceneなど多言語移植も存在し、JVM以外の言語からもLuceneの恩恵を受けられる経路が用意されています。Java開発者が直接Luceneを使って独自検索機能を組み込むケースも多く、特に高度なカスタマイズが必要な業務システムでは今でも一次選択肢になります。
ライブラリと検索サーバの位置付け
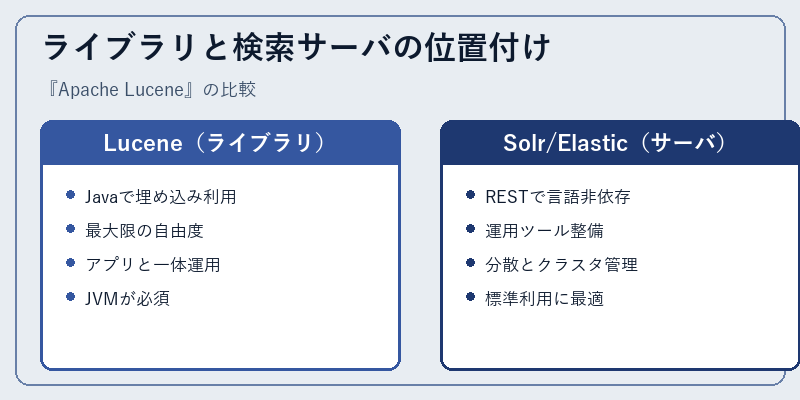
LuceneとSolr/Elasticsearchの違いを一言で言うと「ライブラリと検索サーバ」の違いです。Luceneを直接使うとJavaコードからインデックスとSearcherを操作し、検索ロジックを完全にアプリケーション側で制御できますが、その分REST APIや分散管理、Schemaless運用といったサーバ機能は自前で実装することになります。アプリケーションに「埋め込みの検索機能」を組み込みたい場合、Luceneを直接利用する選択肢はパフォーマンスとフットプリントの両面で優位性があります。
一方、Webサービスとして検索機能を提供する場合、運用性・スケーラビリティ・他言語クライアントの観点からSolrやElasticsearch/OpenSearchを採用するのが現実的です。Lucene自体はライブラリゆえに直接的なユーザー層は限られますが、検索エンジン技術者にとってLuceneの内部構造を理解していることは、これら検索サーバ製品の挙動を深く理解する近道です。Doug Cuttingが残した最大の遺産は、検索という機能を「使えるライブラリ」として民主化したことであり、現代の検索エンジン市場全体がその上に成り立っていると言っても過言ではありません。
まとめ
Apache Luceneは1999年からDoug Cutting氏が育ててきた、Javaの世界標準ともいえる全文検索ライブラリで、Solr・Elasticsearch・OpenSearchなど主要検索エンジンの共通基盤として君臨し続けています。BM25からHNSWベクトル検索まで時代に合わせて進化を続け、検索エンジン技術を学ぶ上でも、現代の検索アーキテクチャを理解する上でも、最初に押さえるべき一本であり続ける存在です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント