
Core-Set法は、機械学習における効率的なサンプリングとモデルトレーニングを可能にするアルゴリズムである。2010年代初頭に提案され、大規模なデータセットからの近似解策定を可能にした。本記事ではその特徴や適用範囲について詳しく見ていこう。
この記事の目次
- Core-Set法の概念
- 歴史的背景
- Core-Set法の仕組み
- 他のサンプリング手法との比較
- まとめ
Core-Set法の概念
Core-Set法は、大規模なデータセットから効果的なサンプル集合を選択する技術である。この方法では、全体のデータの特性を代表する小さな集合体(core-set)が形成され、機械学習モデルのトレーニングや近似解策定に利用される。
具体的には、非凸関数最適化問題に対するCore-Set法は、計算時間を大幅に短縮しつつ、元のデータセットと同等の精度を保証する方法論として注目されている。
歴史的背景

Core-Set法は、非凸関数最適化問題を解く際に初めて提案された。この手法により、高次元空間での計算負荷が大きく抑えられ、実用的な応用範囲が広がった。
その後、データサイエンスや機械学習の分野で、大規模データセットに対するモデルトレーニングに有効な技術として再評価されるようになった。
Core-Set法の仕組み
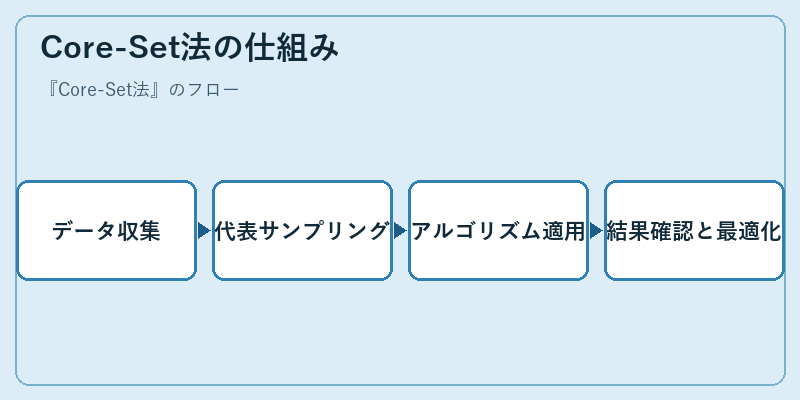
まず、対象となる大量データを収集し、その中からCore-Set法によって代表的なデータ集合を選択する。これは全体のデータの特性やパターンを把握する上で重要なステップである。
次に、選択したcore-setを用いて学習アルゴリズムを適用し、結果を確認する。必要に応じて最適化プロセスを繰り返すことで、より精度の高いモデルを作成することが可能となる。
他のサンプリング手法との比較

Core-Set法は、他の一般的なサンプリング手法と比較して、より高い計算効率と広い適用範囲を提供する。これにより、大規模データセットに対する機械学習モデルのトレーニングが容易になる。
一方で、ランダムサンプリング法は計算効率や精度が限定的であり、特に非凸問題に対しては適さない。これがCore-Set法の優位性を際立たせる。
まとめ
Core-Set法は、大規模データセットに対する機械学習モデルのトレーニングにおいて重要な役割を果たす技術である。その特性や適用範囲について理解しておくことで、より効率的なモデル開発が可能になるだろう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント