
2019年にGoogleによって提唱されたData-Free Distillationは、学習済み大規模な教師あり学習モデルから新しい小さなモデルを生成する手法です。この技術は大量のトレーニングデータを必要としないことで注目を集めました。
この記事の目次
- 定義と背景
- 仕組み
- 比較
- 研究と実装
- まとめ
定義と背景

Data-Free Distillationは、巨大な言語モデルが蓄積する豊富な知識を、トレーニングデータのない状況でも効率よく小さなモデルに転送する技術です。この手法では、大規模な教師あり学習モデルで得られた特徴量や重みを用いて、新たなモデルの初期化を行うことで、学習時間を大幅に短縮できます。
具体的には、大規模モデルを適切にエンコーディングし、その表現力を小さなモデルが引き継ぐ形で設計されます。例えばBERTのような大規模なモデルから、特定のタスク向けの小さなTransformerモデルを作成するといった応用例があります。
仕組み
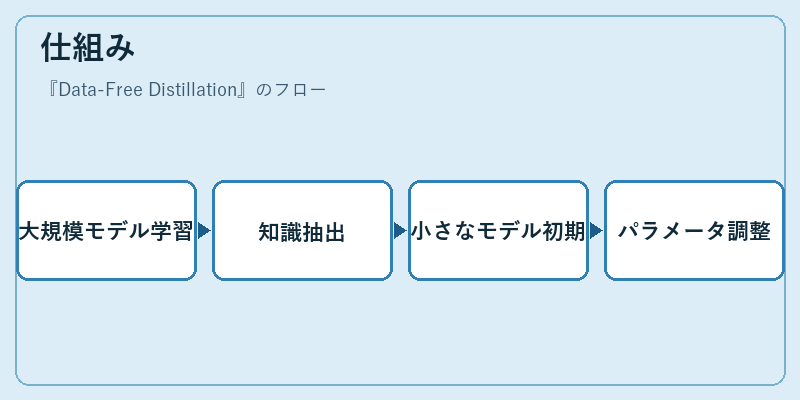
Data-Free Distillationの基本的なワークフローは、まず学習済みの大規模モデルから有用な情報を抽出し、それを小さな新たなモデルに適応させるというものです。この過程では、大規模モデルが獲得した知識を形式化することで、小さなモデルでも同様の性能を達成できます。
実際の手順としては、大規模モデルの層ごとの出力を用いて小さなモデルのパラメータを初期化します。その後、特定タスクに必要な調整を行うことで、大きなモデルと同等かそれ以上の性能を発揮する小型モデルを作り出すことが可能です。
比較

Data-Free Distillationと従来の教師あり学習を比較すると、前者は大量のパラメータや長時間の学習時間を必要とせず、また学習データがなくても大規模モデルから小さなモデルへの知識転送を行うことが可能です。
一方で、教師あり学習では多くのデータと計算リソースが必要となり、またその性能の引き出し方にも制約があります。これに対しData-Free Distillationは、有限なリソースでも効果的なパフォーマンスを達成するための新たな枠組みを提供しています。
研究と実装

Data-Free Distillationは、その効率性と柔軟性から学術的にも多くの注目を集めています。様々な研究者がこの手法の可能性を探求し、それぞれ独自の視点で改良や応用を進めている状況です。
実際のプロジェクトでは、既存の大規模モデルに基づいて小さな特化モデルを開発するための実装例が公開され、その成果が報告されています。これらの研究結果は、将来の機械学習技術開発において重要な指標となることが期待されます。
まとめ
Data-Free Distillationは、大量データと計算資源を必要としない新たな知識転送手法として、AIやデータサイエンス分野における大きな可能性を秘めています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







