
DBSCANは密度に基づくクラスタリング手法で、1996年に被験者データの分析に使われ始めた。非対称性や異常値への耐性を持つことで知られ、従来のK-meansと比べて多様な形状のクラスターを形成できる。
この記事の目次
- DBSCANの定義
- DBSCANの機能
- アルゴリズムのワークフロー
- DBSCANとK-meansの比較
- まとめ
DBSCANの定義
DBSCANは、データポイントが集まり形成する領域を探索し、それらの集合体をクラスターとするアルゴリズムです。この方法は、各データポイントにε近傍という概念を持ち、ε距離内にある点群を用いて定義します。
例えば、ある都市内の人口分布を分析する際に、同様の居住密度を持つ地域を見つけ出し、その集合体をクラスターと見なすことが可能です。これにより都市計画や市場調査などで有益な情報が得られます。
DBSCANの機能

DBSCANは、データの分布が複雑で歪んだ形をもつ場合でも機能します。これにより従来型アルゴリズムでは捉えられなかったクラスター構造を発見することが可能となります。
この特性を利用し、画像解析やウェブサイトのアクセスパターン分析など多くの分野で適用されています。その柔軟性は、DBSCANが今後も広範囲にわたる応用を見込むことを示唆しています。
アルゴリズムのワークフロー

DBSCANは、まず各データポイント間の距離を測定し、指定した範囲(ε)内で他のデータポイントが存在するかどうかを確認します。
次に、その結果に基づき、密な領域内の核となる点を見つける作業を行い、これらを通じて自然と形成されるクラスターを抽出します。このプロセスは全データポイントに対して再帰的に適用されます。
DBSCANとK-meansの比較
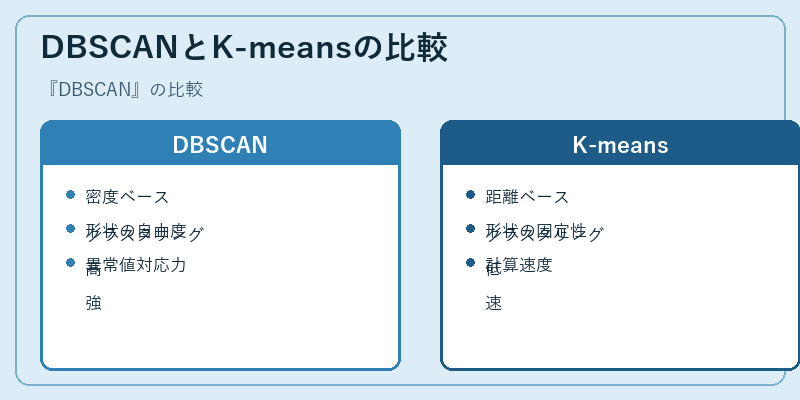
DBSCANは、特定の形に縛られずにデータをグループ化する能力を持つ一方で、K-meansは円錘型や球状のような正規分布されたクラスターに対する優位性があります。
また、異常値を取り扱う際、DBSCANがより柔軟な対処を行えるのに対して、K-meansはそのような値を誤ってグループに含めてしまう可能性があります。このため、データの形態や特性により適したアルゴリズムを選択することが重要です。
まとめ
DBSCANは非線形構造を持つデータに対して優れたパフォーマンスを発揮し、その柔軟性と強力な分析機能から多くの応用が期待されています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







