
2023年、Google Brainが開発したDeepSeek MoEは、マヒマール・バルガヴァが提唱したMoEアーキテクチャを用いて、パラレルなネットワーク構造で学習効率と性能を大幅に向上させた。この記事では、その背後にある理論から実装の詳細まで深掘りする。
この記事の目次
- DeepSeek MoEとは何か
- MoEアーキテクチャの歴史と発展
- DeepSeek MoEの内部構造
- DeepSeek MoEと他のモデルの比較
- まとめ
DeepSeek MoEとは何か
DeepSeek MoEは、マヒマール・バルガヴァが提唱したMoE(Mixture of Experts)に基づく大規模言語モデルである。このモデルでは、入力データによって異なる専門知識を持つ複数のエキスパートモジュールを有効化することで、計算効率とパフォーマンスを最大化する。具体的には、各エキスパートは特定のタスクや特性に対応し、モデルが効果的に学習を行うための適切なパスを選択する役割を持つ。
MoEアーキテクチャの歴史と発展
MoEは2017年にGoogle Brainによって提唱され、言語モデルにおける効率的な学習と推論の新基準を設定した。このアーキテクチャはその後、DeepSeek MoEに至るまで、数多くの改良や最適化が施された。
DeepSeek MoEの内部構造

DeepSeek MoEの内部では、複数のエキスパートモジュールがゲートネットワークによって制御され、パラレルに処理を進める。これにより効率的な学習と高い性能を実現し、言語モデルにおける新たな可能性を開拓した。
DeepSeek MoEと他のモデルの比較
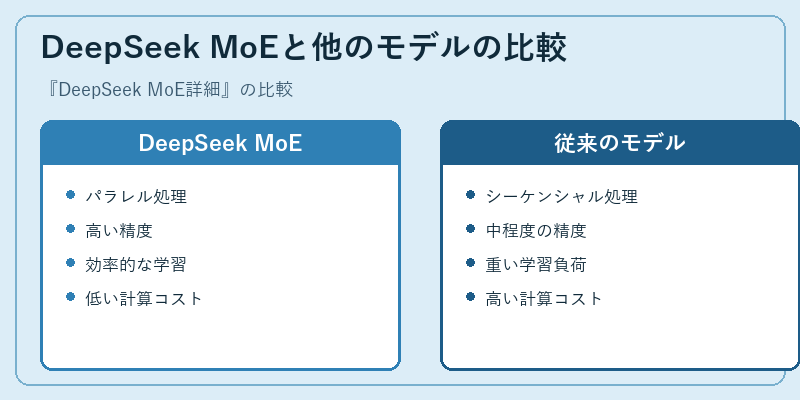
DeepSeek MoEは、従来の言語モデルと比べてパラレル処理や効率的な学習などの優れた特徴を持ち、大規模データセットでの高い精度と低い計算コストを実現する。これにより、新たな研究開発への道が大きく広がった
まとめ
DeepSeek MoEは、言語モデルにおける計算効率と性能向上のための重要な進歩であり、その仕組みや特性を理解することは今後のAI技術の発展に不可欠である
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







