
Dense Retrievalは、機械学習における自然言語処理(NLP)分野で進化を遂げた手法です。2019年に提出された「DPR」という研究から始まったこの技術は、従来のSparse Retrievalに代わる新たな情報検索モデルとして広く受け入れられつつあります。
この記事の目次
- Dense Retrievalの定義と起源
- Dense RetrievalとSparse Retrievalの比較
- Dense Retrievalの仕組み
- Dense Retrievalの応用例
- まとめ
Dense Retrievalの定義と起源
Dense Retrievalは、文書とクエリをベクトル空間で近接させることにより、関連性の高い情報を高速に見つけ出す方法です。この技術は2019年にIBMによって提案され、BERTのようなTransformerベースのモデルを用いることで実現されました。
例えば、ウェブ検索エンジンではDense Retrievalが従来のSparse Retrievalと比べて大幅なパフォーマンス向上を示しています。
Dense RetrievalとSparse Retrievalの比較

Dense RetrievalとSparse Retrievalの主な違いは、文書エンベディングの方法にあります。前者ではTF-IDFなどの統計的手法が用いられますが、後者では深層学習モデルが導入されています。
この違いにより、Dense RetrievalはスケーラビリティにおいてSparse Retrievalより劣るものの、高い精度と高速な検索を可能にしています。
Dense Retrievalの仕組み
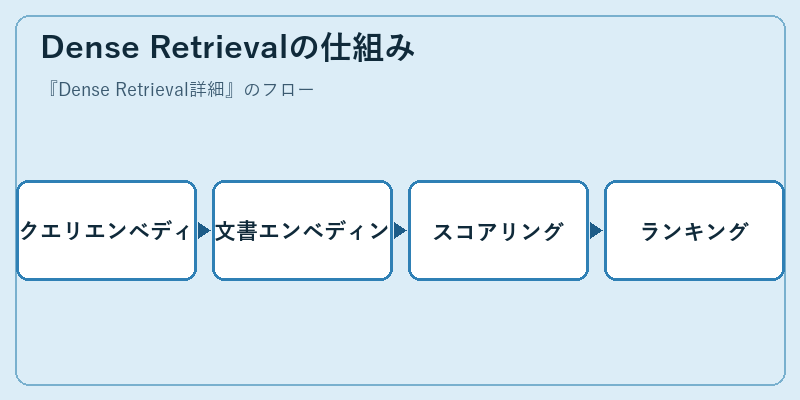
Dense Retrievalは、まず入力された自然言語のクエリとドキュメントそれぞれに対して、深い学習モデルを使用してベクトル表現を生成します。
その後、生成した文書ベクトル群からクエリベクトルとのスコアリングを行い、その結果に基づいて関連度の高い順にランキング付けを行います。
Dense Retrievalの応用例
Dense Retrievalは、検索エンジンやQ&Aシステムなど、幅広い応用分野でその優れた性能を発揮しています。これらの技術では、Dense Retrievalがクエリとドキュメントの関連性を迅速に評価することで利用されます。
情報要約やコンテキスト理解といった高度なNLPタスクでも、Dense Retrievalは重要な役割を果たしています。
まとめ
高速かつ高精度な検索が求められる現代のデジタル環境において、Dense Retrievalは新たな情報アクセス方法として大きな可能性を秘めています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







