
誤差逆伝播(Backpropagation)は、ニューラルネットワークの各重みに対する損失関数の勾配を、出力層から入力層へ向かって連鎖律で効率的に計算するアルゴリズムです。1986年にRumelhart、Hinton、Williamsの論文で広く知られるようになり、多層パーセプトロンの学習を現実的な計算量で可能にしたことで、現在の深層学習ブームの直接的な礎となりました。本稿ではアルゴリズムの仕組み、計算グラフとの関係、自動微分による実装、典型的な落とし穴までを丁寧に解説します。
この記事の目次
- 誤差逆伝播の仕組みと連鎖律
- 計算グラフと自動微分による実装
- 歴史的背景と深層学習復活への貢献
- 勾配消失・爆発と現代的な対策
- まとめ
誤差逆伝播の仕組みと連鎖律
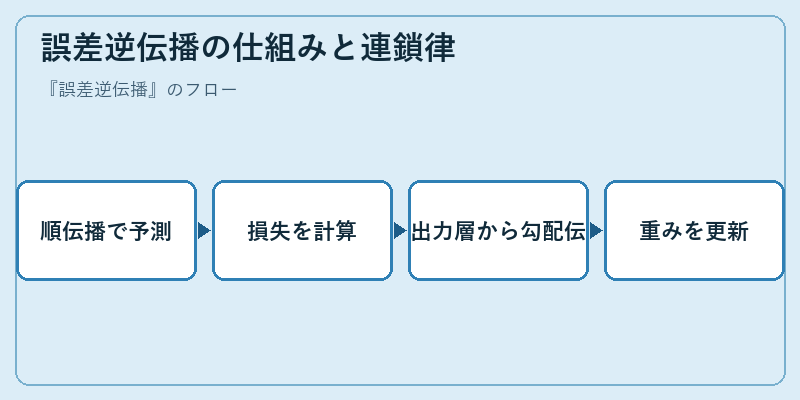
誤差逆伝播はまず順伝播でネットワークに入力を流し、各層の出力と最終的な予測値を計算します。次に予測値と正解ラベルから損失を求め、その損失に対する各重みの偏微分を計算するのですが、ここで連鎖律(chain rule)を使うのがポイントです。出力層側で計算した勾配を一段ずつ入力層側へ伝播させることで、全パラメータの勾配を計算量オーダーO(パラメータ数)で求めることができます。
数式的には、ある層の重みに対する勾配は、その層の出力に対する勾配と、その層への入力との外積で表現されます。連鎖律により、出力層側で計算済みの勾配を再利用しながら下位層へと伝えていけるため、各重みについて個別に数値微分を行うのに比べて圧倒的に効率的です。この効率性こそが、何百万・何十億ものパラメータを持つ現代の深層モデルを学習可能にした技術的ブレークスルーといえます。
計算グラフと自動微分による実装
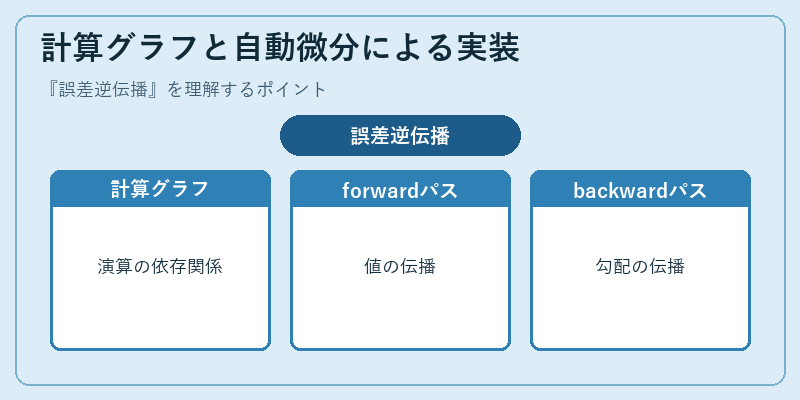
現代のフレームワークは誤差逆伝播を「計算グラフ+自動微分」という抽象で実装しています。順伝播時にどの演算がどの値を生成したかをノードとエッジで記録し、逆伝播時にはその逆順にたどりながら各演算の局所勾配を計算・合成します。PyTorchはeager modeで計算グラフを動的に構築し、TensorFlowはかつてstaticグラフを採用していましたが、現在はeager実行も統合され、利用者は数式に近い形でモデルを記述するだけで自動的に勾配が得られます。
この仕組みのおかげで、研究者は新しい層やカスタム損失関数を設計するときも、forward処理さえ正しく書けばbackwardはほぼ自動で導出されます。複雑な分岐や条件分岐、ループを含むモデルでも勾配が得られるため、Transformerのような巨大アーキテクチャや、強化学習で見られる方策勾配の計算など、多様な学習スキームを統一的に扱えます。誤差逆伝播は理論的な枠組みであると同時に、現代の深層学習エコシステムの中核技術でもあります。
歴史的背景と深層学習復活への貢献
誤差逆伝播のアイデア自体は1960年代から存在し、Werbosの博士論文(1974年)が先駆的とされていますが、機械学習コミュニティに広く認知されたのは1986年のRumelhart、Hinton、Williamsによる論文です。当時は多層ニューラルネットワークの学習方法が確立されておらず、AIの研究は「冬の時代」と呼ばれる停滞期にありましたが、この論文を契機にバックプロパゲーションが標準的な学習手法として普及しました。
ただし1990年代から2000年代前半までは、勾配消失問題や計算資源の不足によって深いネットワークの学習は依然として難しく、SVMなど他の手法に押される形となります。状況が一変したのは2006年のHintonによる事前学習論文や、2012年のAlexNetによる画像認識ブレークスルーであり、ReLU、ドロップアウト、GPU、大規模データセットといった要素と組み合わさることで、誤差逆伝播は現代の深層学習の標準アルゴリズムとして再評価されました。
勾配消失・爆発と現代的な対策

誤差逆伝播の最大の弱点は、層が深くなるほど勾配が指数的に小さく(消失)または大きく(爆発)なりやすいという点です。シグモイドのような飽和する活性化関数は勾配が0.25未満になるため、何層も掛け合わさると入力層付近の勾配がほぼゼロになります。これが2010年代前半まで深いネットワークの学習を阻んできた根本的な障害でした。
現在では、ReLUやGELUといった非飽和系の活性化関数、HeやXavierといった分散を考慮した重み初期化、バッチ正規化や層正規化、そして残差接続(スキップコネクション)を組み合わせることで、勾配を安定して伝えられるようになっています。Transformerでは層正規化の位置(Pre-LN/Post-LN)や残差接続の設計、勾配クリッピングが学習の安定性を大きく左右し、現代の巨大モデルはこれらの工夫の積み重ねで成立しています。
まとめ
誤差逆伝播は、連鎖律という基本的な数学を効率的なアルゴリズムへと昇華させ、深層学習の幕を開けた歴史的発明です。計算グラフと自動微分により実装は劇的に簡単になりましたが、勾配消失や爆発、初期化、正規化といった実装上の知見と組み合わせて初めて、巨大モデルの安定した学習が実現できます。理論と実装の両面を理解することが、深層学習を扱う技術者の出発点となります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント