
CNN(Convolutional Neural Network、畳み込みニューラルネットワーク)は、画像のような格子状データに対して空間的な局所性と平行移動不変性を活かして特徴を抽出する深層学習モデルです。1989年のLeCunによるLeNetを起点に、2012年のAlexNet以降は画像分類・物体検出・セグメンテーションといった視覚タスクで圧倒的な精度を実現し、現代AIブームの火付け役となりました。本稿では畳み込み演算の原理、代表的アーキテクチャ、画像以外への応用、Transformerとの関係までを整理します。
この記事の目次
- 畳み込み・プーリング・全結合の三層構造
- LeNetからResNetまで主要アーキテクチャの系譜
- 画像認識を超えた幅広い応用領域
- Vision Transformerとの比較と現代の位置づけ
- まとめ
畳み込み・プーリング・全結合の三層構造
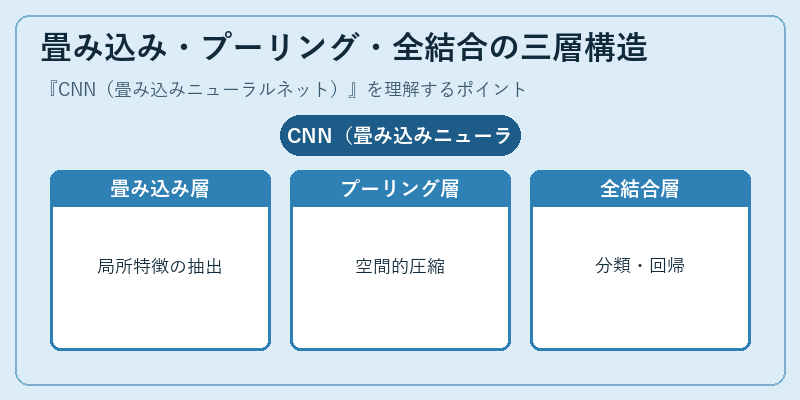
CNNの基本構造は、畳み込み層、プーリング層、全結合層という三種類の層の組み合わせで成り立っています。畳み込み層は小さなフィルタ(カーネル)を画像上でスライドさせ、各位置で内積を計算することで、エッジやテクスチャ、形状といった局所特徴を抽出します。同じフィルタを画像全体で共有することで重みの数が劇的に減り、平行移動に対するロバスト性も得られます。
プーリング層は数ピクセル単位で最大値や平均値を取って空間サイズを縮小し、計算量を抑えつつ抽出特徴に対する小さなずれへの不変性を高めます。複数の畳み込み・プーリング層を重ねることで、低層では線やコーナー、中層では模様や部品、高層では物体全体といった階層的な特徴が学習されます。最後に全結合層やGlobal Average Poolingでクラス確率や回帰値を出力する構造が、長らくCNNの標準形でした。
LeNetからResNetまで主要アーキテクチャの系譜

CNNの歴史はLeCunが郵便番号認識のために設計したLeNet(1989年)に始まり、長らく注目されない時代が続きましたが、2012年のImageNetコンペティションでAlexNetが従来手法を10ポイント以上引き離す精度を叩き出したことで一気に表舞台へ躍り出ました。AlexNetはReLU、ドロップアウト、データ拡張、GPU学習という現代深層学習の要素を初めて統合した記念碑的モデルです。
その後VGGは3×3畳み込みの単純な積み重ねで深さの重要性を示し、GoogLeNet(Inception)は計算効率を追求する並列モジュールを導入しました。2015年のResNetは残差接続によって150層以上の超深層ネットワークを学習可能にし、勾配消失問題に対する事実上の解答を示しました。以降、DenseNet、EfficientNet、ConvNeXtといったアーキテクチャが登場し、計算量と精度のトレードオフが洗練され続けています。
画像認識を超えた幅広い応用領域
CNNは画像分類だけでなく、物体検出やセマンティックセグメンテーション、インスタンスセグメンテーションといった多様な視覚タスクで活躍しています。YOLOやSSDといった一段階検出器はリアルタイム性に優れ、自動運転や監視カメラに広く使われています。医療画像のがん検出、衛星画像の地物分類、製造業の外観検査など、ドメイン特化型の応用も枚挙にいとまがありません。
また一次元畳み込みは音声波形や時系列データ、テキストの埋め込み列にも適用でき、波形分類や異常検知に使われます。三次元畳み込みは動画解析や医療ボリュームデータで有効です。CNNは「局所性と並進不変性が成り立つデータ」全般に適用できる汎用的なアーキテクチャであり、ドメインに応じたカスタム設計の自由度が高いことが、長年にわたる人気の理由となっています。
Vision Transformerとの比較と現代の位置づけ

2020年のVision Transformer(ViT)の登場以降、画像認識の主役はTransformer系モデルへと移りつつあります。ViTは画像をパッチに分割してSelf-Attentionで処理し、十分大きなデータセットで事前学習すればCNNを上回る精度を達成します。一方でデータ量が少ない場合はCNNの局所性帰納バイアスが有利に働き、両者は補完的な関係にあります。
近年はConvNeXtのようにTransformer的な学習レシピをCNNに取り入れた手法が、ViTと同等以上の性能を示すケースも報告されています。また、Swin Transformerのように畳み込み的な階層構造をTransformerに組み込むハイブリッド設計が主流になりつつあり、CNNとTransformerの境界はあいまいになってきました。ローカルな特徴抽出にCNN、グローバルな関係性にAttentionという役割分担が、今後も視覚AIの標準パラダイムとして続いていくと考えられます。
まとめ
CNNは、画像の局所性と平行移動不変性という構造的特性を活かす設計によって、画像認識を中心とする視覚AIに革命をもたらしました。ResNetが切り開いた超深層化、YOLOやU-Netに代表される応用展開、ViTやConvNeXtとの相互発展を通じて、CNNは今後も視覚タスクの基盤技術として進化を続けます。問題のスケールと特性に応じて適切なアーキテクチャを選ぶ目利きが、実務での成功を左右します。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント