
Self-Attention(自己注意)は、入力系列の各要素が同じ系列内の他のすべての要素を参照して関係性を計算する機構で、2017年の論文「Attention is All You Need」でTransformerの中核として導入されました。RNNや畳み込みに頼らず、文全体の長距離依存関係を一度に捉えられる柔軟性と並列計算可能性によって、自然言語処理から画像認識まであらゆる分野に革命をもたらしました。本稿では仕組み、Multi-Head化、計算量、応用までを詳しく解説します。
この記事の目次
- Self-Attentionの基本的な計算手順
- Multi-Head Attentionによる多視点学習
- 計算量とスケーラビリティの課題
- Transformerを介した広範な応用と影響
- まとめ
Self-Attentionの基本的な計算手順
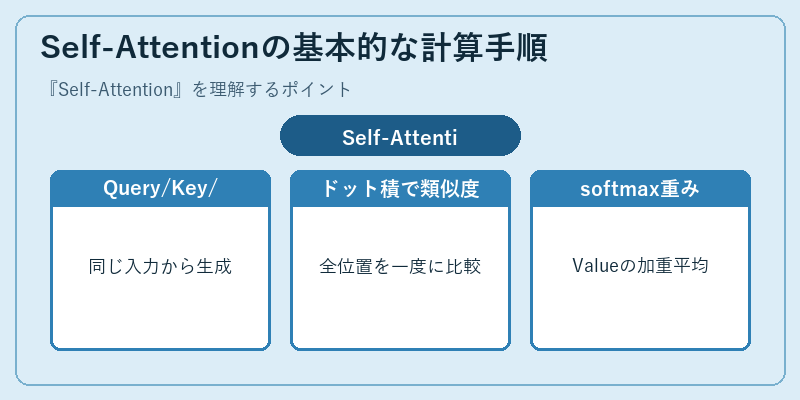
Self-Attentionは、入力系列の各位置のベクトルから線形変換でQuery、Key、Valueの三つを生成するところから始まります。次にQueryとKeyのドット積を計算して位置間の類似度行列を作り、それをキー次元の平方根で割って正規化し、softmax関数で重みに変換します。最後にこの重みでValueの加重平均を計算することで、各位置の新しい表現が得られます。
重要なのは、QueryもKeyもValueも同じ入力系列から作られている点で、これが「自己」注意と呼ばれるゆえんです。これにより、文章中のある単語が文の他のどの単語と関連が深いかをモデルが直接学習でき、係り受けや指示語、文脈依存の意味解釈を表現できます。一回のSelf-Attentionで全位置から全位置への情報伝播が可能なため、長距離依存も一段階で処理できる強力な仕組みです。
Multi-Head Attentionによる多視点学習

単一のSelf-Attentionだけでは表現力が限られるため、Transformerでは複数のSelf-Attentionを並列に実行するMulti-Head Attentionが採用されています。入力ベクトルを複数のヘッドに分割し、各ヘッドが独立してQuery・Key・Valueを生成して別々のAttentionを計算し、最後に結果を連結して線形変換で統合します。
それぞれのヘッドは異なる種類の関係を学習するとされ、あるヘッドは構文的な係り受けに、別のヘッドは意味的な共起関係に、また別のヘッドは語順情報に注目する、といった役割分担が実証研究で観察されています。これにより一つの層で多様な視点から系列の構造を捉えられ、表現力が大幅に向上します。ヘッド数の典型値はBERTやGPTで8や12、16などが採用されます。
計算量とスケーラビリティの課題
Self-Attentionは系列内の全ペアの関係を計算するため、計算量とメモリ使用量が系列長Nの二乗(O(N²))でスケールするという課題があります。短い文章では問題にならないものの、長文書や高解像度画像、長時系列を扱う際にはメモリ不足や計算時間の爆発が起きやすく、これは大規模モデルにとって本質的な制約となります。
この問題に対し、Sparse Attention、Linformer、Performer、Longformer、Flash Attentionといった効率化手法が次々と提案されてきました。Flash AttentionはGPUメモリ階層を巧みに活用して計算速度とメモリ効率を改善し、現代の長文LLMでは標準的に採用されています。また、2023年以降は状態空間モデル(Mamba等)が線形時間で長系列処理を行う代替案として注目され、Self-Attentionの計算量問題を回避する研究も活発に進められています。
Transformerを介した広範な応用と影響

Self-Attentionを中核とするTransformerはまず機械翻訳で成功を収め、その後BERT、GPT、T5、Llamaといった大規模言語モデルへと発展して自然言語処理の標準となりました。2020年のVision Transformer(ViT)以降は画像認識でも主流となり、Swin TransformerやDINOといった派生モデルがCNNを置き換える勢いで普及しています。
さらに、音声認識のWhisper、音声合成、動画理解、医療画像解析、AlphaFoldなどタンパク質構造予測まで、Self-Attentionは分野を問わず深層学習の標準ツールとなりました。テキスト・画像・音声を統合的に扱うマルチモーダルAIでも中心的役割を果たし、CLIPやGemini、GPT-4のような汎用AIモデルの基盤となっています。Self-Attentionは21世紀の深層学習を象徴する技術であり、その影響はまだまだ広がり続けています。
まとめ
Self-Attentionは、同じ系列内のすべての要素が互いを参照しながら表現を更新するという発想で、深層学習の構造設計を根本から変革しました。Multi-Headによる多視点学習、Transformerへの組み込みを経て、自然言語処理から画像・音声・科学計算まであらゆる領域で標準技術となっています。計算量の課題に対する効率化研究も活発で、Self-Attentionは今後も生成AI時代の中核を担い続けるでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント