
EasyEnsembleClassifierは、過剰適合を防ぎながら予測精度を向上させるための機械学習手法です。特に少数クラス問題やデータバイアスに強い特徴があり、近年のディープラーニングに次ぐ人気を集めています。
この記事の目次
- アンサンブル学習の原理
- 特徴量選択とサンプリング技術
- 過学習と欠陥点
- 他のアンサンブル方法との比較
- まとめ
アンサンブル学習の原理
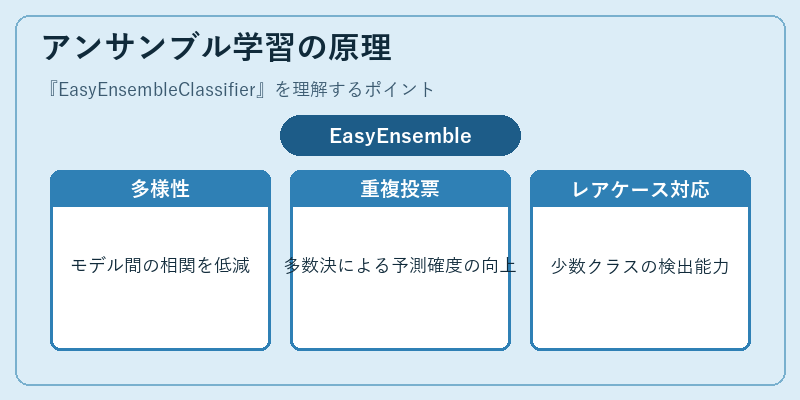
EasyEnsembleClassifierは、多数の基底学習器(通常ランダムフォレストやSVMなど)を集合させて、全体的な予測精度と汎化性能を向上させます。これにより。
例えば、金融機関の詐欺検知システムでは、複数のモデルが異なる視点からデータを取り扱うため、重要な異常信号を見逃すリスクが低減されます。
特徴量選択とサンプリング技術

特徴量選択とサンプリングは、モデルの性能向上に不可欠な工程であり、EasyEnsembleClassifierではこれらを高度に統合しています。
ある医療画像診断アプリケーションで、SMOTEや欠損値処理が導入されると、珍しい病変パターンの検出精度も改善されました。
過学習と欠陥点

EasyEnsembleClassifierは過学習を抑える一方で、大きな計算量とモデル複雑さのトレードオフがあります。最適なパラメータ調整が必要です。
大規模なデータセットを持つウェブサービスでは、この手法が実装されたことで、予測精度は向上しましたが、リアルタイム応答性に課題も生じました。
他のアンサンブル方法との比較

EasyEnsembleClassifierは、BaggingとBoostingの強みを組み合わせつつ新たなアプローチを提供します。ただし、他の手法との比較では、それぞれ異なる利点があります。
ある消費者行動分析システムでは、EasyEnsembleClassifierが少数クラス問題に対処する一方で、Baggingが全体的な安定性を確保し、Boostingは細かな学習進化を促しました。
まとめ
さまざまなシナリオにおいて効果的に活用できるEasyEnsembleClassifierの潜在能力に注目しながら、適切なパラメータチューニングとデータ準備に焦点を当てることが重要です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







