
2010年にApache Luceneプロジェクトから派生した Elasticsearchは、高度な検索と分析を可能にするオープンソースフルテキスト検索エンジンとして知られる。Networking詳細では、そのネットワーク通信プロトコルやデータ同期のメカニズムについて掘り下げていく。
この記事の目次
- Elasticsearchの通信アーキテクチャ
- ネットワーク同期とデータ冗長性
- データ同期と可用性確保
- 他の検索エンジンとの比較
- まとめ
Elasticsearchの通信アーキテクチャ
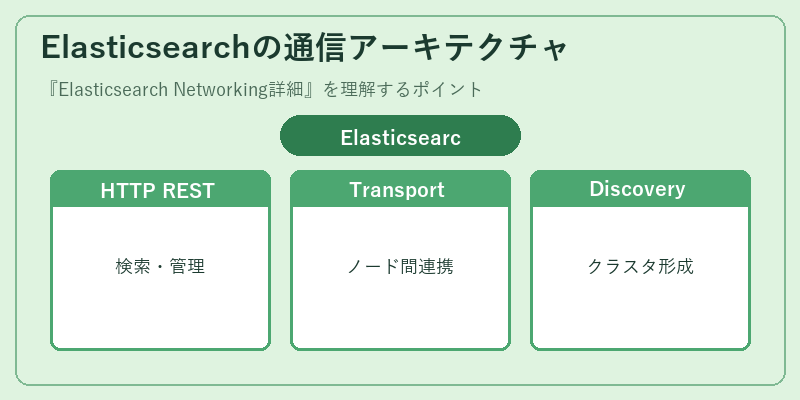
Elasticsearchの通信は、主に三つの軸で構成されている。HTTP REST APIとTransport TCPプロトコルが中心となる一方、Discovery Zenはネットワーク内でのクラスター作成を担っている。
REST APIを用いてクライアントがサーバーに検索要求を行う際には、後方互換性の高いJSONメッセージフォーマットを利用し、Transport TCP経由で複数ノード間通信を行う。さらにDiscovery Zenはその機能により一貫したクラスタ環境を構築する役割を果たすのである。
ネットワーク同期とデータ冗長性

Elasticsearchでは、データの冗長性確保やクラスタ内の同期を担う複数機能が用意されている。まずはReplication因子設定によってシャードコピーを作成し、障害発生時の復旧対策を講じる。
またPeer-clone機能は特定ノード間でのデータ再同期を促進し、ネットワークの一時的な問題や個別ノードのダウンによる影響を最小限に抑える。Gateway snapshotsを通じて定期的にクラスタ全体の状態をバックアップすることで、災害時の迅速な復旧が可能となるのである。
データ同期と可用性確保

ネットワーク同期プロセスは、まずクラスタの設定から始まる。この段階では、Replication因子やShard分散配置といった重要なパラメータが決定される。次に各ノード間でデータの同期作業が行われる。
その後は定期的な監視を実施し、エラー発生時にはPeer-cloneを通じた復旧処理を行いつつ必要に応じて設定調整を行うことになるのである。
他の検索エンジンとの比較

ElasticsearchはHTTP REST APIやTransport TCPプロトコルを用いたネットワーク通信を特徴とする。これに対してSolrでは、XMLまたはJSON形式のPOSTメソッドによる情報やり取りが中心となる。
またクラスタ管理においても両者に違いがあり、ElasticsearchはDiscovery Zenを通じたシンプルなプロセスでクラスタを作成する一方、SolrはZookeeperを経由してクラスタを形成し維持する方式を採用しているのである。
まとめ
ElasticsearchのNetworking詳細については、通信アーキテクチャやネットワーク同期、データ冗長性などを含む多岐にわたる側面を理解することが重要である。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







