
DPOは、ユーザーや組織の目的に合わせた行動推奨を行う機械学習技法です。1980年代から研究が進み、2010年代後半には企業でも広く採用されるようになりました。
この記事の目次
- 直接選好最適化とは
- DPOの起源と進化
- DPOの内部構造
- DPOと他の最適化手法の違い
- まとめ
直接選好最適化とは
DPOは、個々のユーザーがどのような行動を取るべきかを予測する手法です。具体的には、過去の行動パターンから未来の選択肢とその結果を推定します。
このテクノロジーにより、マーケティングやサービス設計においてユーザーエンゲージメントの最大化に向けた戦略が立てやすくなります。
DPOの起源と進化
DPOの発展は、統計学や経済理論からの多くの影響を受けました。ベイジアンモデルなどが基礎となって、ユーザー選好をより精密に推測することが可能になりました。
しかし一方で、個人情報保護への懸念も高まり、プライバシーと利便性のバランスを模索する必要が生じています。
DPOの内部構造
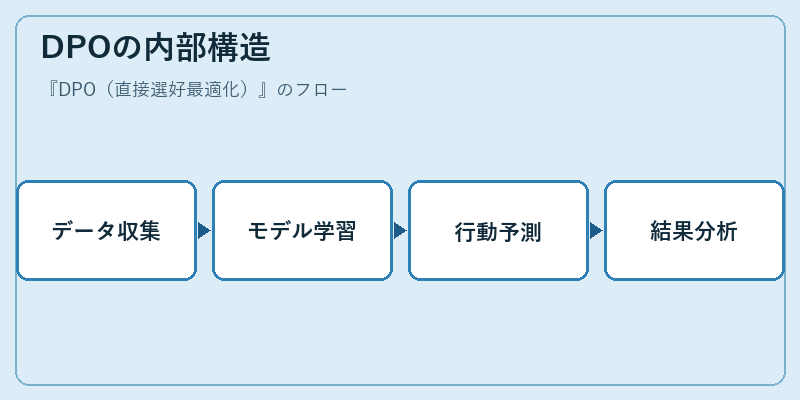
DPOシステムは、まずユーザーや顧客の行動データを広範に収集します。その後、これらのデータを元にして機械学習モデルを訓練し、特定の状況下での最適な行動パターンを予測します。
最終的に得られた結果は、実際のユーザー選好と照らし合わせてフィードバックが行われます。このサイクルにより、システム全体がより高度化していきます。
DPOと他の最適化手法の違い

DPOは他の最適化手法と比べ、より個々の行動選択に焦点を当てています。具体的には、ユーザーがどのようなアクションを取りたがるかを深く理解しようとします。
対する他手法は、全体としての効率やコスト削減を目指すことが多いです。それぞれのアプローチは異なる状況でその力を発揮し、選択肢としては互いに補完的な役割を果たしています。
まとめ
DPOはユーザー行動を予測し最適化する技術であり、企業のマーケティング戦略やサービス設計において重要な位置を占めています。今後もこの分野における進展に注目が集まることでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント