
アマゾンウェブサービス(AWS)が提供するAmazon EMR Serverlessは、SparkやHadoopなどのデータ処理フレームワークをサーバーレスで実行可能にします。この記事ではEMR Serverlessの特徴、機能、および他のサーバーレスサービスとの比較を通じて、クラウドにおけるデータ処理アプローチについて掘り下げます。
この記事の目次
- EMR Serverlessの仕組み
- EMR Serverlessと他のサーバーレスサービスの違い
- EMR Serverlessが解決する課題
- エコシステムとの連携
- まとめ
EMR Serverlessの仕組み

EMR Serverlessは、ユーザーがクラスターやサーバーの管理に費やす手間を最小限にするための設計となっています。これにより、デプロイや維持といった通常の作業を自動化し、リソースの動的なスケーリングを行うことが可能になります。
さらにEMR ServerlessはSparkとHadoopの処理エンジンをサポートしており、これらを基盤とするさまざまなビッグデータ分析タスクに対応します。具体的には、大量のログファイル解析やリアルタイムストリームデータの検討など、あらゆる種類の大規模データセットに対する迅速な分析が可能となるのです。
EMR Serverlessと他のサーバーレスサービスの違い

AWS上で他の多くのサーバーレスサービスと共に存在するEMR Serverlessですが、そのユニークな役割はビッグデータ処理に特化している点です。この性質により、Lambda等の関数エッジ計算とは一線を画すものとなっています。
たとえば、ビッグデータ解析が必要となる場合、ユーザーはEMR Serverlessを通じてHadoopやSparkといったフレームワークを利用可能となります。一方で、短時間のタスク処理やイベント駆動型アプリケーション開発などにはLambdaのようなサービスが最適な場面が多いでしょう。
EMR Serverlessが解決する課題

EMR Serverlessが提供する主な価値は、これらの利点を通じてユーザーの課題解決に貢献することです。具体的には、サーバーインフラを自ら構築・維持せずとも効率的なビッグデータ処理が可能となるのです。
たとえばある企業では、自社開発製品の大量ユーザーデータ分析のためにEMR Serverlessを利用し、既存システムからの大きな負荷を取り除くことに成功しました。このような事例はEMR Serverlessがビッグデータ処理分野で広範に活用されていることを示しています。
エコシステムとの連携
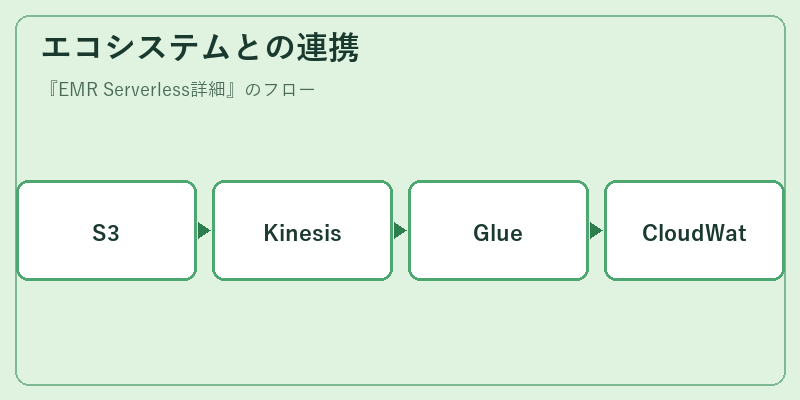
EMR ServerlessはAWSプラットフォームの一部として位置づけられ、他の多くのサービスと連携することでより高度なソリューションを提供します。例えば、S3ストレージからデータ取得後、KinesisストリーミングやGlueカタログを使用してデータ処理・統合を行います。
その後に得られた洞察はCloudWatchを通じて可視化され、更なるアクションにつなげることが可能となります。このようにEMR Serverlessと他のサービスの連携により、一貫性のあるビッグデータ処理フローを実現することができます。
まとめ
EMR Serverlessはビッグデータ処理におけるサーバーレスアプローチをより効果的に推進し、その結果ユーザーが直面する課題の解決に大きく貢献します。その他のサーバーレスサービスとの違いや連携性も理解しておくことが重要です。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







