
Entity Embeddingは、機械学習や自然言語処理において特徴量エンジンとして機能します。文字列データを高次元空間内の点として表現することで、類似性の判別を可能とし、2015年頃から研究開発が活発化しています。
この記事の目次
- Entity Embeddingの定義
- Entity Embeddingの歴史
- Entity Embeddingの仕組み
- Entity EmbeddingとOne-Hot Encodingの比較
- まとめ
Entity Embeddingの定義
Entity Embeddingは、文字列の意味をベクトル化する技術です。それぞれのデータ要素が高次元空間での点として表現され、類似性に基づく分析が可能となります。
例えば、商品名や顧客属性といったカタログデータもベクトルに変換されます。こうすることで、これらのデータ間で関連性を検出することが容易になります。
Entity Embeddingの歴史

Entity Embeddingの始まりはWord2Vecというテキスト処理技術に遡ります。このアルゴリズムによって、単語が文脈によりベクトル表現されるようになりました。
その後、Doc2VecやKG Embeddingなどの進化型手法が登場し、より複雑なデータセットを扱えるようになりました。
Entity Embeddingの仕組み
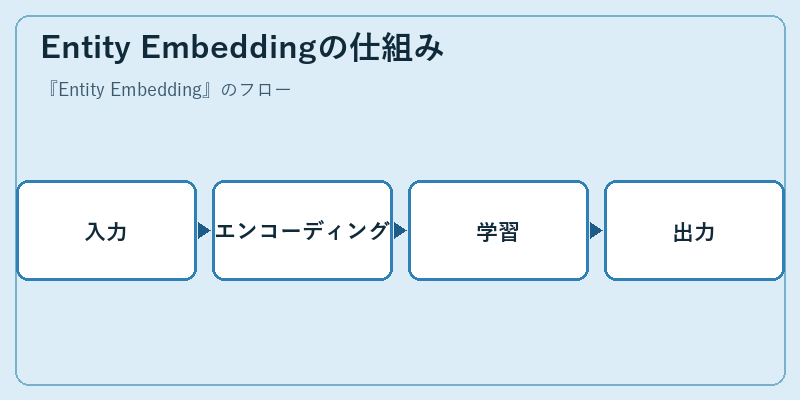
Entity Embeddingは、まず対象データを特徴量として抽出します。これにより元のデータ形式からベクトル表現へと変換されます。
次に、このベクトル化されたデータを用いて学習を行い、それぞれの要素が持つ文脈情報に基づく重み付けが行われます。
Entity EmbeddingとOne-Hot Encodingの比較

Entity Embeddingは、従来型のOne-Hot Encodingとは異なる特質を持っています。特に文脈による要素間関係性を考慮します。
一方で、One-Hot Encodingでは個々の要素に1つだけ重みが割り当てられますが、Entity Embeddingはそれぞれの要素間に文脈情報を反映させるため、より細かい違いを捉えることができます。
まとめ
Entity Embedding技術は、データ分析における新たな視点を提供し続けています。今後もこの領域での研究開発が進むことが予想されます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







