
機械学習(Machine Learning、ML)は、明示的なルールを書く代わりに大量のデータからパターンを抽出してタスクをこなす技術の総称です。1959年にIBMのアーサー・サミュエルが造語したと言われており、長い研究の蓄積を経て2010年代以降のディープラーニング革命とビッグデータの整備により実用フェーズに入りました。本記事では機械学習の基本枠組み、代表的な手法、ビジネス適用までを整理します。
この記事の目次
- 機械学習の3つの学習スタイル
- 代表的なアルゴリズム
- 機械学習プロジェクトの典型的な流れ
- 機械学習とAIの関係
- まとめ
機械学習の3つの学習スタイル
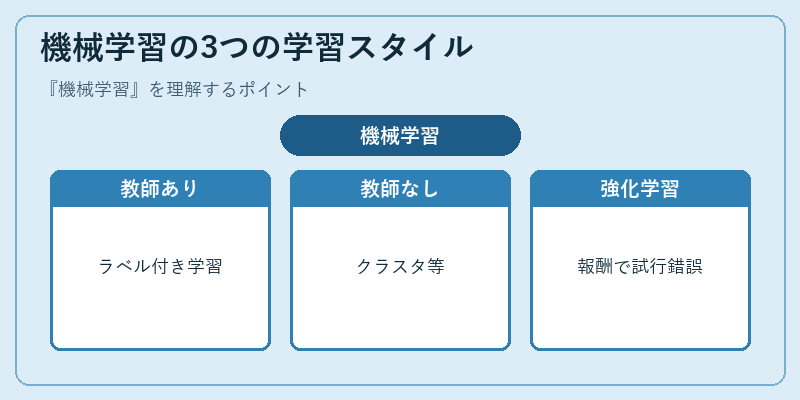
機械学習は問題設定の違いで「教師あり学習」「教師なし学習」「強化学習」の3つに大別されます。教師あり学習は入力と正解(ラベル)のペアから関係を学ぶ方式で、迷惑メール判定、画像分類、需要予測など実用ケースの大半を占めます。
教師なし学習はラベルのないデータから構造を見つけるアプローチ(クラスタリング、次元削減など)。強化学習は囲碁AIのAlphaGoや自動運転で注目された、「環境と相互作用しながら報酬を最大化する」枠組みです。問題が決まれば、おのずと使うべき学習スタイルも見えてきます。
代表的なアルゴリズム

機械学習アルゴリズムは数多くありますが、実務で頻出するのは線形回帰・ロジスティック回帰・決定木系(ランダムフォレスト、XGBoost、LightGBM)・サポートベクターマシン・ニューラルネットワークあたりです。
とくに表形式データのコンペで最強と言われるのが勾配ブースティング系で、Kaggleの上位解法は10年近くこの系統が支配的でした。画像・音声・自然言語のような非構造データになるとディープラーニングが圧倒的優位、という棲み分けで覚えると整理しやすくなります。
機械学習プロジェクトの典型的な流れ
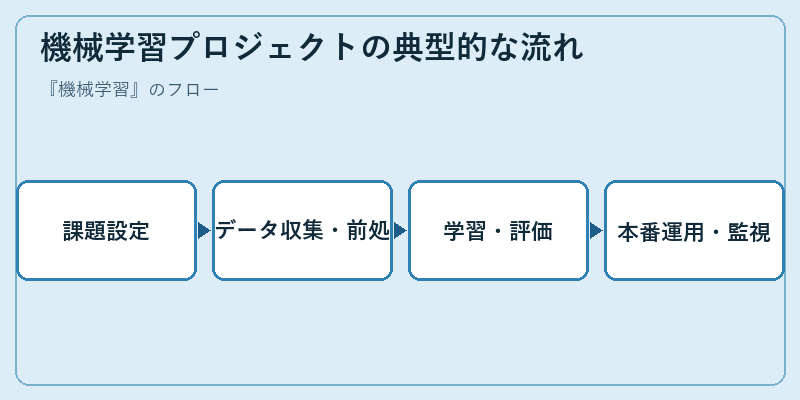
機械学習プロジェクトはモデル選びより、その前段の課題設定とデータ整備で勝負がほぼ決まります。「予測したいことは何か」「何を入力にできるか」「外れた時のコストは」という業務側の問いを詰めずに進むと、技術的に完璧でもビジネスに使えないモデルが生まれがちです。
本番化(MLOps)も独立した重要トピックです。学習データと本番データの分布がずれる「データドリフト」、再学習のタイミング、予測値の監視・ロールバック、特徴量ストア整備など、「動くモデル」を「使い続けられるシステム」にするには別腕の技術が要ります。
機械学習とAIの関係

「機械学習」「AI」「深層学習」「生成AI」は混同されがちですが、関係を整理すると、AI(人工知能)が一番広く、その中に機械学習があり、機械学習の中にニューラルネットを使う深層学習が含まれ、深層学習の応用のひとつが生成AI、という入れ子の構造になっています。
ビジネスの場では現在「AI」と呼ばれているもののほとんどは機械学習や深層学習を指していると考えてほぼ間違いありません。用語の正確さを求めるなら「機械学習」「深層学習」と呼ぶ方が誤解が少なく、技術文書では使い分けを意識する価値があります。
まとめ
機械学習はビジネスに直結する応用が出揃ったため、技術者にとって基礎教養に近い位置づけになりました。アルゴリズムだけでなく、データ整備・運用・倫理まで含めて理解しておくと、AI時代の実務での意思決定に大きな差が出ます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント