
Microsoftが開発したFairlearnは、機械学習モデルにおける偏りと不平等を最小限に抑えるためのツールキットです。2018年に登場し、倫理的なAI研究の一環として注目を集めています。
この記事の目次
- 公平性評価と改善
- 実装と統合
- データ偏りへの対策
- Fairlearnとその他のツール
- まとめ
公平性評価と改善
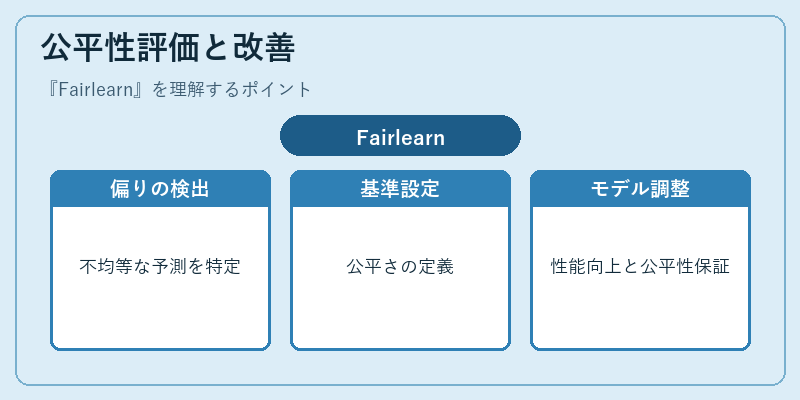
Fairlearnは機械学習モデルの訓練時に生じる潜在的な偏りを検出します。これには、グループごとの予測差分分析やオーバーサンプリングなどが含まれます。
具体的な使用例として、Fairlearnは教育プログラム推薦システムにおいて、少数派の学生が適切に支援を受けられるよう公平性を向上させました。
実装と統合
FairlearnはPythonで開発されており、他の機械学習ライブラリと統合可能。MLflowやTensorBoardなどと共に利用することで、開発プロセスを効率的にします。
Fairlearnの評価指標は訓練フェーズに組み込まれ、モデルが予測する際に特定のグループに対して不公平な結果にならないよう、事前にチェックを行います。
データ偏りへの対策

Fairlearnは、データ偏りを抑えるための多様なアプローチを提供します。過剰サンプリングやアンダーサンプリングなど、訓練セットに存在する不均衡を修正し、学習モデル全体の性能と公平性を向上させます。
これらの手法は、特定のユーザーセグメントへのサービス改善に役立ちますが、一方で全員にとって最適な結果となるとは限らないため、バランスを取りながら適用することが重要です。
Fairlearnとその他のツール

Fairlearnと他の公平性向上ツールを比較すると、後者は主に予測精度に基づいてモデル選択を行う傾向があります。これに対しFairlearnは、データの不均衡や偏りを考慮した評価基準を提供します。
しかし、FairlearnにはRubyやClojureでの実装がサポートされていないため、これらの言語を使っている開発者は別のツールを探す必要があります。
まとめ
機械学習モデルの公平性向上は重要な課題であり、Fairlearnのようなツールはそれを可能にします。多様なアプローチと柔軟性により、開発者は偏りを最小限に抑えつつ最適なモデルを作り出すことができます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







