
2016年にGoogle Brainチームが提唱した聯邦學習算法FedAvgは、ユーザー端末上で機械学習モデルをローカルに訓練し、中央サーバーとデータ共有を行う仕組み。この手法はプライバシー保護やスケーラビリティ向上に貢献。
この記事の目次
- FedAvgの定義
- FedAvgの背景
- FedAvgの実装
- FedAvgと分散学習の比較
- まとめ
FedAvgの定義
FedAvgは、多数のデバイス間で機械学習モデルを訓練するためのフレームワークです。デバイス上のデータを使用してモデルが個別に更新され、その変更点だけが中央サーバーと共有されます。
例えば、医療アプリケーションでは患者情報の保護が必要であり、各端末でローカル学習を行い、パラメータをクラウドへ送信することで効果的にプライバシーを守ります。
FedAvgの背景

Google Brainチームは、大きなデータセットを必要とする場合やプライバシー問題に直面する状況での学習を改善するためにFedAvgを開発しました。
それにより、大量のデバイスが参加し、それぞれのユーザーのデータを保護しつつ、全体的なモデル性能向上を目指すことが可能になります。
FedAvgの実装
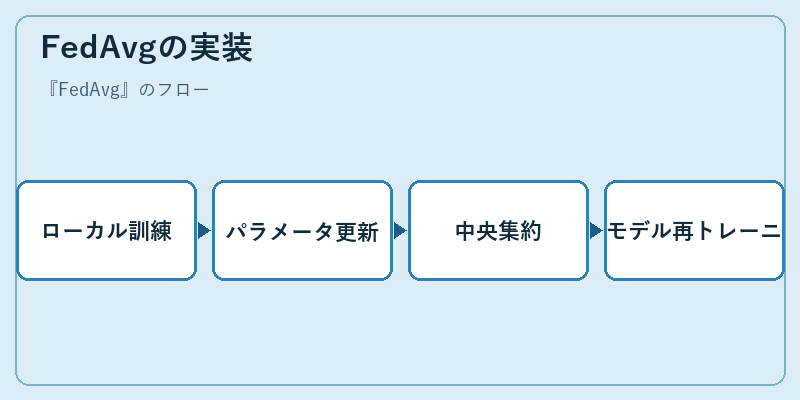
開発者はまず、各デバイス上でローカルデータを用いてモデルを訓練します。その後、その結果であるパラメータが中央サーバーへ送られます。
サーバー側ではこれらの情報を統合し、全体のモデルが更新され再トレーニングが行われます。このプロセスは反復的に行われることで効果を発揮します。
FedAvgと分散学習の比較
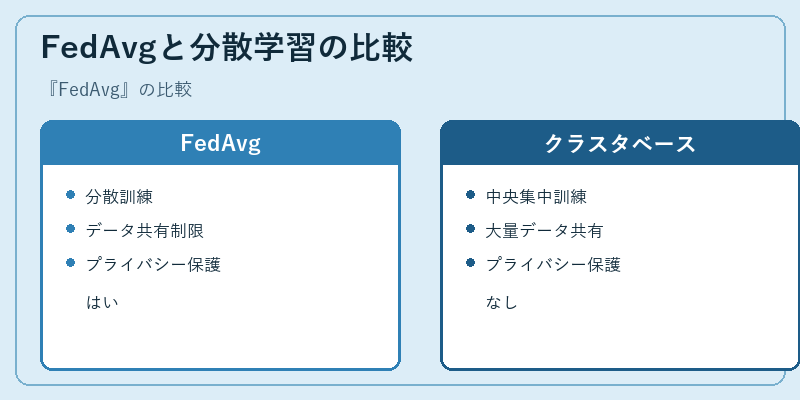
FedAvgと従来の分散学習アプローチを比較すると、パラメータの送信だけを行うため、全体的な通信量が抑えられます。これにより、デバイス間でのデータ共有も制限されるのでプライバシー保護がより容易になります。
一方で、クラスタベースのアプローチでは大量のデータを中央サーバーに集約し、処理を行います。これは効率的である反面、ユーザーの情報は安全性を問われる可能性があります。
まとめ
FedAvgは機密性とスケーラビリティを両立させたフレームワークとして注目を集め、今後の研究開発における重要な役割を果たしつつあります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







