
FixMatchは2020年に発表され、半教師あり学習手法として広く認識されている。データラベルの不足を補うために生まれたこの技術は、画像分類タスクにおける性能向上に大きく貢献した。
この記事の目次
- FixMatchの基本概念
- FixMatchの発展と応用
- FixMatchの実装手法
- FixMatchと他の半教師あり学習法の比較
- まとめ
FixMatchの基本概念
FixMatchは、強化学習と教師なし学習の境界で進化した概念である。再帰的アタックと対立エントロピーによる不確実な予測のフィルタリングがその鍵となる。
例えば、犬猫の画像分類において、未ラベルのデータからモデルが混乱する可能性のあるパターンを検出し、それらは再学習の過程で排除される。このプロセスにより、半教師あり学習は新たなレベルに達したのである。
FixMatchの発展と応用

FixMatchは半教師あり学習の枠組みをさらに推し進め、特に大量の未ラベルデータが利用可能な状況で有用である。
この手法は医学画像分析や産業製品検査などでも大きな期待を集めている。これらの分野ではデータラベルの作成に伴うコストと時間が問題となっているため、FixMatchのような技術は不可欠となる。
FixMatchの実装手法
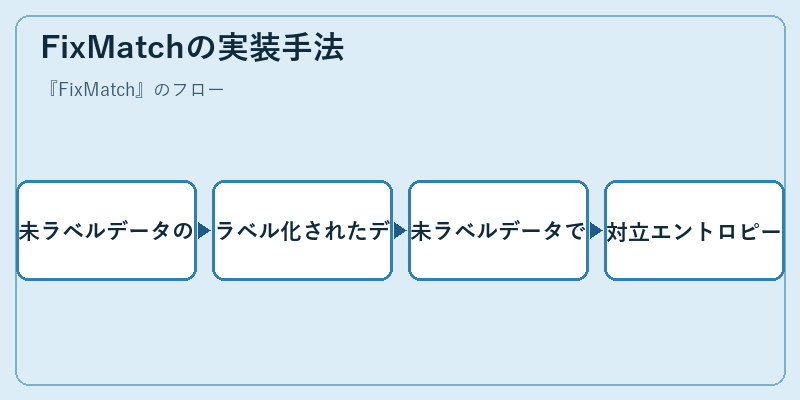
FixMatchは複雑なステップを経て実装される。まず、未ラベルデータを前処理して学習可能な形に整える。
次に、既存のラベル化されたデータセットを用いてモデルをトレーニングし、その上で未ラベル化のデータで推論を行う。対立エントロピーが低いと予測は通過し、高ければフィルタリングされるのである。
FixMatchと他の半教師あり学習法の比較
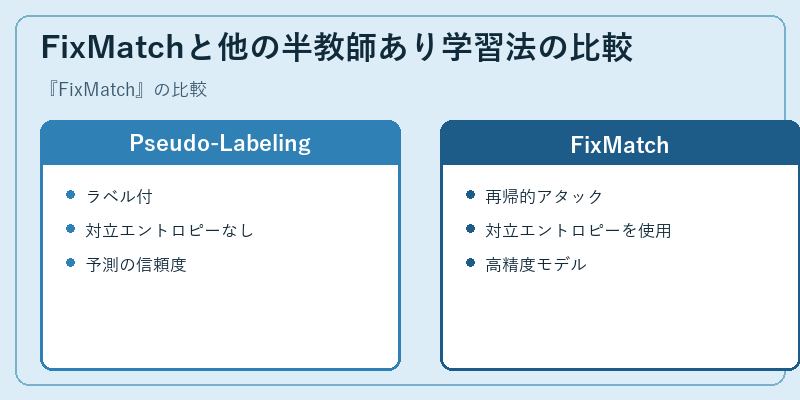
Pseudo-Labelingと比較して、FixMatchは不確実な予測を効果的に排除することで性能の向上を図る。
またFixMatchは再帰的アタックにより学習済みの知識を利用し、高精度なモデル生成に貢献する。これに対しPseudo-Labelingは対立エントロピーを使用せず、信頼度が低い予測も受け入れる傾向がある。
まとめ
FixMatchは半教師あり学習の新しい地平を開き、未ラベルデータを効果的に活用する手段として注目を集めている。これからもこの手法は進化し続けることだろう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







