
1960年代に発表されたこのアルゴリズムは、データストリーム解析において欠損値や過剰な情報を素早く検出する手法として知られる。本記事ではフォードファルカーソン法の背景とその機能を詳しく見ていき、現代的な応用についても考察する。
目次
この記事の目次
- アルゴリズムの特徴
- 開発と普及
- 技術的背景
- 他の手法との比較
- まとめ
アルゴリズムの特徴
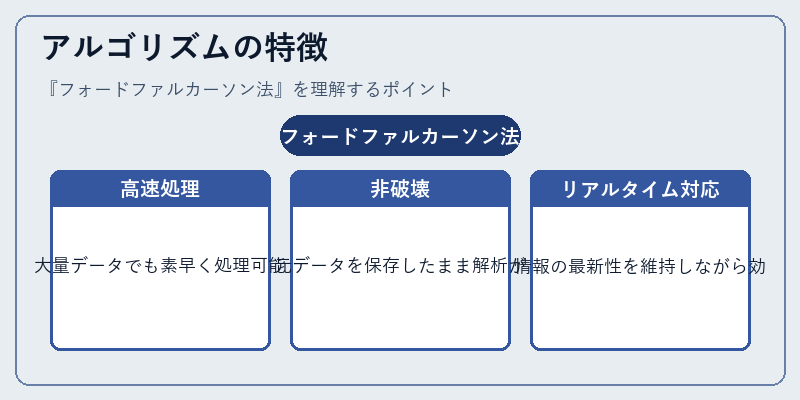
アルゴリズムの主要な利点と強みを明示する。例えば、大量データを高速に処理できることや、元データが保存されるため再解析が容易であるといった特徴が挙げられる。
具体的にはオンライン分析システムやネットワークトラフィックモニタリングでその効果が顕著に現れる。それらの例を用いてアルゴリズムの実際の動作と有用性を説明する。
開発と普及
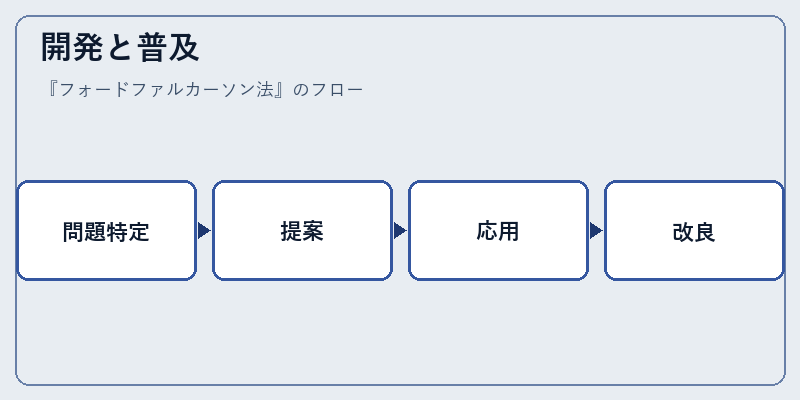
このアルゴリズムは、初期の計算機時代におけるデータ処理技術の進歩を象徴するものとして開発された。
具体的には1960年代にエドガー・フォードとロナルド・ファルカーソンが共同で提出し、その後さまざまな分野へ普及していった経緯について述べる。
技術的背景

フォードファルカーソン法は、特定の統計手法と連携して効果的に動作する。それらの基礎となる数学的理論や計算能力について紹介。
アルゴリズムがどのような条件下で最大限のパフォーマンスを発揮するのか具体的な例とともに詳述。
他の手法との比較

フォードファルカーソン法の利点を強調しつつ、それと比較される他の方法論の特性も触れる。
具体的には、リアルタイム解析が必要な場合に比べてどの程度フォードファルカーソン法が優れているかを例示することで、その有用性を再確認する。
まとめ
データストリーム分析において重要な役割を果たすフォードファルカーソン法について考察した。このアルゴリズムの幅広い応用可能性と高度な効率性は、今後の技術進化にも大きく貢献すると期待される。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







