
ガウス混合モデル(GMM)は、19世紀にカール・フリードリヒ・ガウスによって提唱された正規分布を基盤とし、現代のデータサイエンスやパターン認識で幅広く用いられる手法です。本記事ではその定義から推定プロセスまで詳しく解説します。
この記事の目次
- ガウス混合モデルの定義
- GMMの学習過程
- GMMの主な用途
- GMM vs. K-means
- まとめ
ガウス混合モデルの定義

ガウス混合モデルは、複数のガウス(正規)分布を適切な重み付けして組み合わせたもので、データ点がその中のどの分布から出ているかを推定する。
具体的には、あるデータセットが異なるガウス分布の集合から生成されたと仮定し、それぞれの分布に属する可能性を計算します。
GMMの学習過程
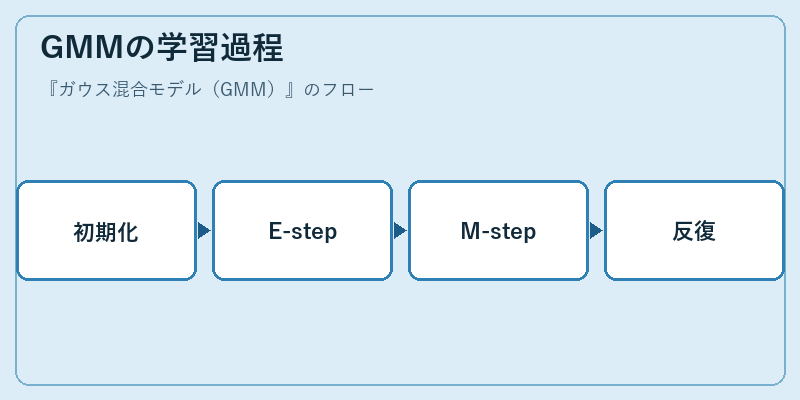
ガウス混合モデルのパラメータ推定には、EM(期待値最大化)アルゴリズムが用いられます。この過程は、確率分布を更新しながら収束に向かいます。
まず初期パラメータ設定を行い、その後Eステップでは各データ点の混合成分に属する尤度を計算します。そしてMステップで最適なパラメータを求め続けます。
GMMの主な用途

ガウス混合モデルは、主にデータのクラスタリングや異常値の検知といった分野で活用されています。また、特定の分布を生成するための密度推定にも効果的です。
たとえば音響信号処理ではノイズ除去のためフィルタリング技術として、画像分析では複雑な形状やパターンを持つ物体の識別に利用されます。
GMM vs. K-means

ガウス混合モデルは、データ点間の重複可能性を考慮する一方で、K-meansでは各データポイントが特定の一意なクラスタに割り当てられることになります。
この違いによりGMMはより柔軟な形状を持つクラスターを生成できますが、計算コストが高くなるというデメリットがあります。
まとめ
ガウス混合モデルは多様なデータ解析や機械学習タスクに応用可能な高度な確率モデルで、その解釈可能性と柔軟性が多くの場面で有用であることが示されています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







