
GRACE(Gradient-based Row-wise Clustering and Encoding)は、大規模なデータセットでの学習を高速化する機械学習手法です。2017年に提出された論文で注目を集め、その後多くの研究者がその応用範囲を広げました。
この記事の目次
- GRACEの定義と原理
- 歴史と発展
- 仕組み: グラデーションベースのクラスタリング
- 他の圧縮技術との比較
- まとめ
GRACEの定義と原理
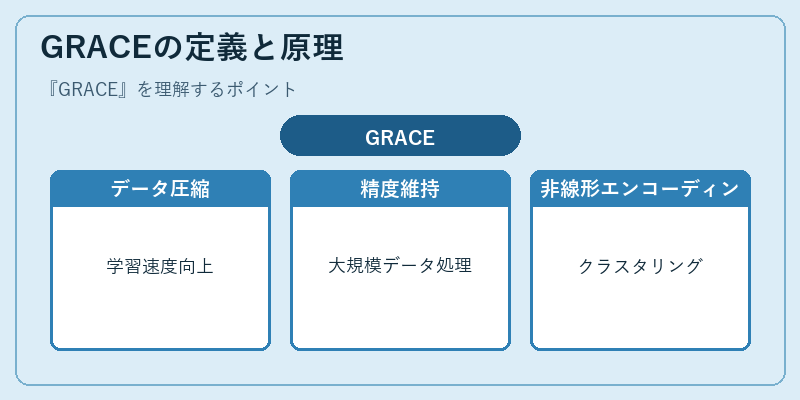
GRACEは、高次元空間での非線形エンコーディングと階層型クラスタリングの原理を用いて、データセットを圧縮します。これにより機械学習モデルのパフォーマンスを向上させます。
具体例として、大量の画像データに対するモデル訓練では、GRACEは複雑な特徴抽出を効率化し、モデル収束時間を短縮できます。
歴史と発展
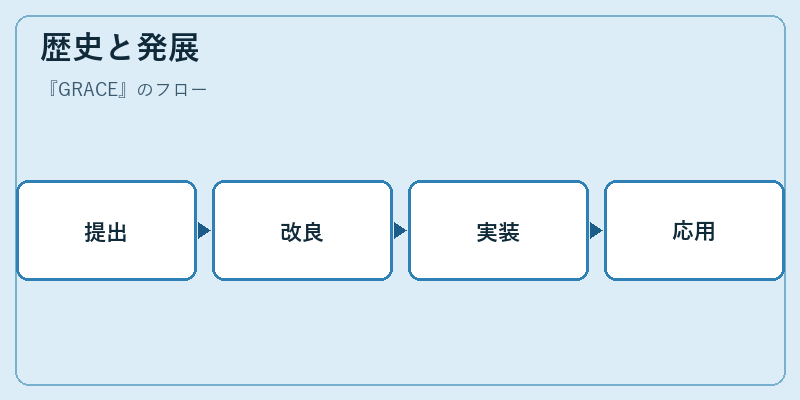
GRACEは2017年に論文で最初に提案され、その後さまざまな研究者がその可能性を追求しました。初出の後すぐに多くの改良版が登場し、学習アルゴリズムやエンコーディング戦略が進化しました。
現在では、各種データセットへの応用事例が増え、精度と効率のバランスを探求する動きがあります。これにより新たな研究領域が開かれつつあります。
仕組み: グラデーションベースのクラスタリング

GRACEは、各データ点の勾配情報を元に階層型クラスタリングを行い、それぞれをグループ化します。これにより効率的なエンコーディングが可能となり、モデルパフォーマンスの向上が期待できます。
また、非線形性を考慮したエンコーディングは従来の手法よりも情報量が多く、精度の高い学習結果を得られます。こうした点から、GRACEは大規模なデータセット処理に適しています。
他の圧縮技術との比較
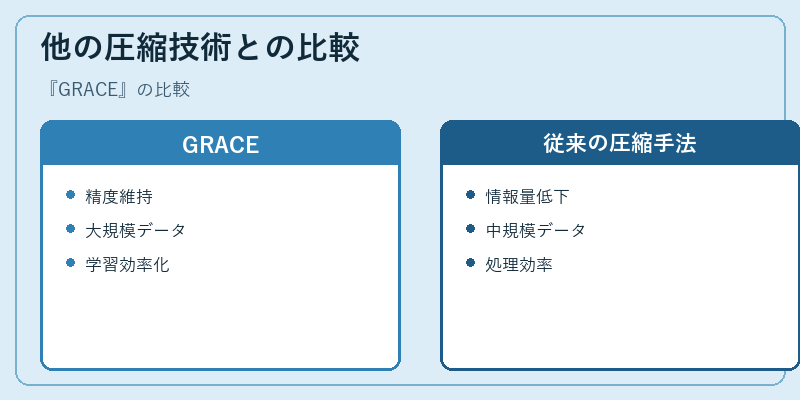
GRACEと従来の圧縮技術を比較すると、情報損失が少ない点で前者は優れています。しかし、計算リソースや学習時間に対する負担も考慮する必要があります。
また、モデルパフォーマンスへの影響も重要な視点です。これらの違いを理解することは、最適な圧縮技術の選択に役立ちます。
まとめ
GRACEは大規模データセットでの学習効率化と精度維持を両立させようとする先端的な機械学習手法です。その原理や適用範囲を理解することは、次世代のデータ処理技術への道しるべとなります。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







