
A3C(Asynchronous Advantage Actor-Critic)は2016年にデミス・ハサブネスと同事によって提案された強化学習アルゴリズムです。複数のエージェントが非同期で学習を行うことで効率を高め、DeepMindのアトミックプレイなどに応用されました。
この記事の目次
- A3Cの定義と目的
- A3Cのアルゴリズム構造
- A3Cと他の強化学習手法
- A3Cの実装と応用
- まとめ
A3Cの定義と目的
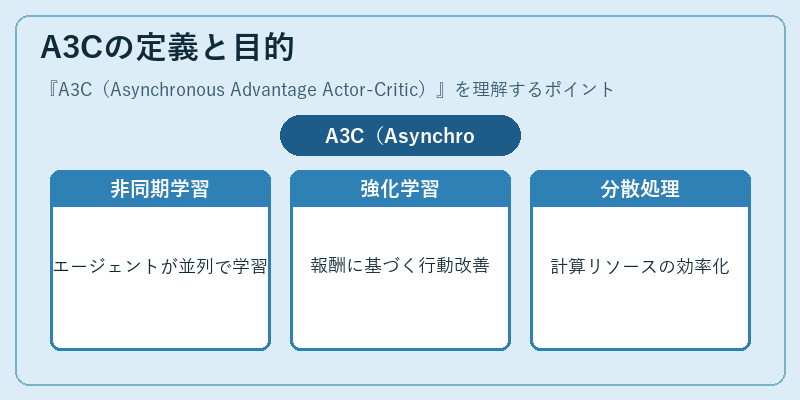
A3Cは、複数のエージェントが非同期で学習を行う強化学習アルゴリズムです。これにより、エージェント間での干渉を最小限に抑えつつ、計算資源の活用を最大化します。
このアプローチは、単一エージェントによるシーケンシャルな学習よりも速く、かつより効果的なパラメータ更新を可能とします。これにより、大規模な環境での効率的な強化学習が実現できます。
A3Cのアルゴリズム構造
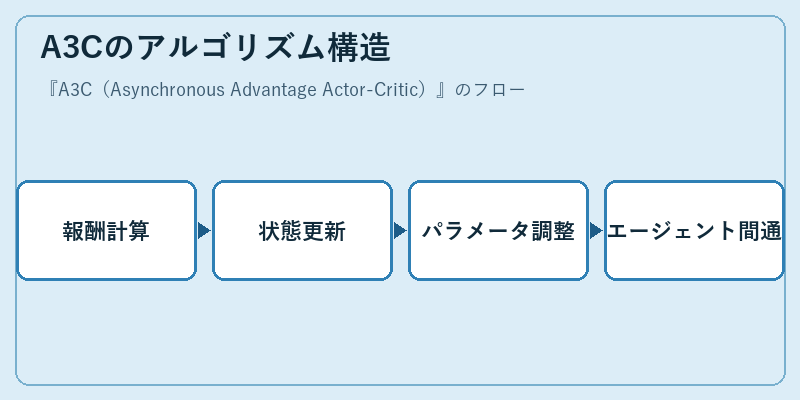
A3Cは、Actor(行動決定)とCritic(評価)の双方を組み合わせた学習システムです。これにより、行動の効果的な評価が可能となります。
具体的には、各エージェントは自己の状態から最適な行動を選択し、その結果として得られた報酬と状態遷移に基づいて学習パラメータを更新します。このプロセスは複数のエージェント間で並行に行われます。
A3Cと他の強化学習手法
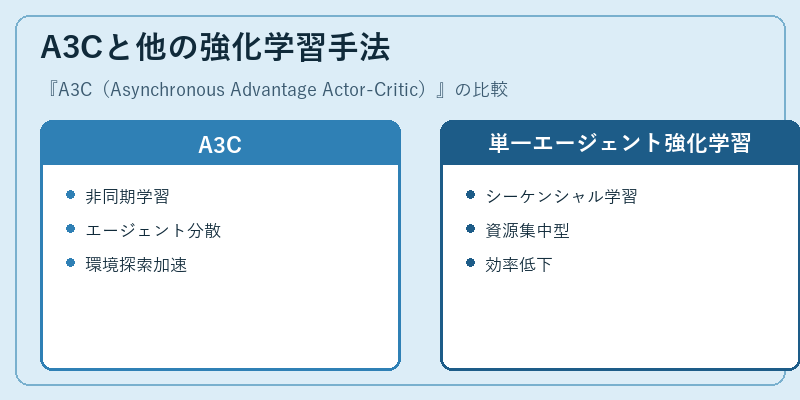
A3Cは従来の強化学習手法とは異なるアプローチを採用しています。非同期で複数エージェントが並行して学習を行うことにより、環境の探索や問題解決における効率性が向上します。
一方、従来の単一エージェント型強化学習はシーケンシャルなプロセスに依存し、資源の集中利用を避けることが難しいため、より多くの計算時間が必要となります。
A3Cの実装と応用

A3Cの実装には、並列で動作するエージェント群を効率的に管理するための技術的工夫が必要となります。また、非同期通信を通じたパラメータ更新は学習効果に大きな影響を与えます。
具体的な応用例としては、ゲームプレイやロボット制御などへの展開が見られています。A3Cはこれらの分野における高度化を目指す研究者にとって有用なツールとなります。
まとめ
A3Cは強化学習の分野において並列処理を導入することで、従来よりも効率的な学習が可能となりました。今後も、その応用範囲とアルゴリズムの進化に注目したいところです。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント