
Haystackは、大規模データセットを効率的に管理するためのフレームワークです。1980年代から発展し、近年では機械学習モデルのトレーニングデータ整理にも活用されています。
この記事の目次
- Haystackの定義と役割
- Haystackの歴史
- Haystackの内部仕組み
- Haystackの競合比較
- まとめ
Haystackの定義と役割
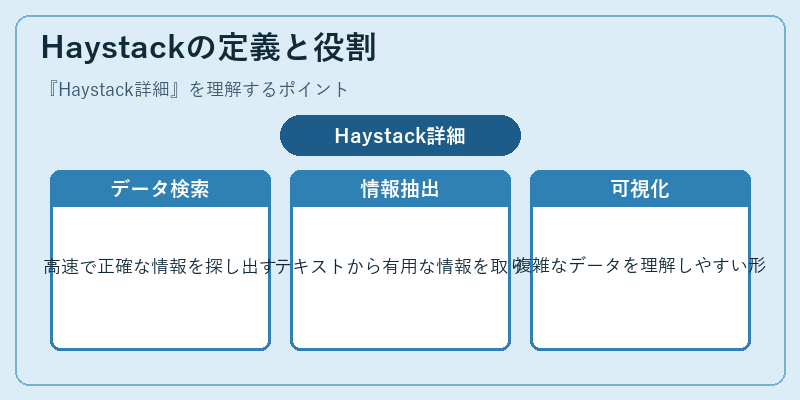
Haystackは、検索エンジンや機械学習モデルのための大規模データセット管理に特化したフレームワークである。これにより、大量のテキストや画像データから必要な情報を効率よく取り出すことが可能になる。
具体的には、複数の検索エンジンと連携して情報を取り込むことで、一元的なビューを提供する。この機能は、デジタルアーカイブやビジネスインテリジェンスツールにおいて特に重要となる。
Haystackの歴史
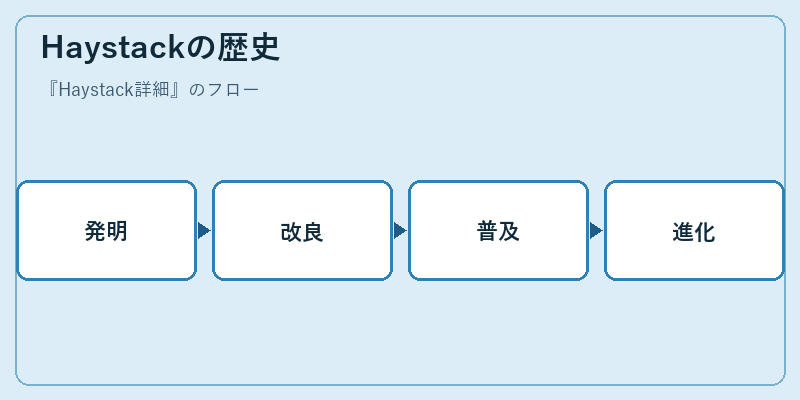
1980年代、データベース技術が進歩とともにHaystackも生まれた。初期のバージョンでは基本的な検索機能と情報抽出のみを提供していたが、その後の年月を通じて高度な可視化ツールや統合型アーキテクチャへと発展した。
2000年代に入ると、インターネットの普及とともにHaystackは多くの組織に採用され、その有用性は広く認知されるようになった。現在ではAI技術との親和性が高まり、更なる進化を遂げている。
Haystackの内部仕組み

Haystackは、インデックス構築と高度な検索エンジン技術を統合することで、大量のデータから迅速に必要な情報を探し出す能力を持つ。これにより、ユーザが直感的な操作で情報を取得することが可能となる。
さらに、そのフレキシブルなアーキテクチャは、新たな機能やサービスとの連携にも適しており、柔軟性と拡張性を備えている。
Haystackの競合比較
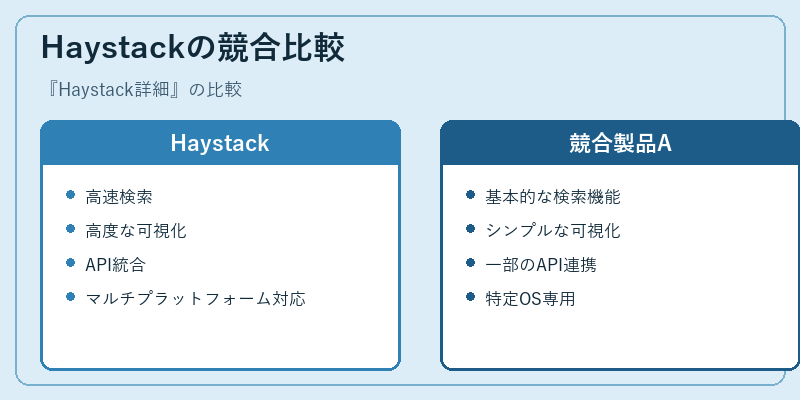
Haystackは、速度と精度を兼ね備えた検索エンジンと高度な情報抽出能力で市場を席巻する一方、競合製品Aはより基本的な機能に重点をおいている。
ただし、Haystackは複数のプラットフォームやAPIとの連携を可能にする柔軟性があり、これによって他のソリューションにはない利点を生み出している。
まとめ
現代のデジタル環境において、データ検索と可視化はますます重要になってきている。Haystackはそのニーズに適切に対応し続ける技術として注目を集め続けている。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







