
2020年に登場したHaystackは、自然言語によるクエリ応答を可能にするオープンソースプロジェクトとして注目を集めました。その核心となるコンポーネントの構造と役割について深掘りします。
目次
この記事の目次
- データインデックスの構築
- コンポーネントの相互作用
- アーキテクチャの歴史と進化
- Haystackとその他のシステム比較
- まとめ
データインデックスの構築

Haystackのインデックスは、文書から抽出された情報をベクトル空間にマッピングし、高速なクエリ応答を可能にする。
たとえば、Wikipediaや研究論文などの大量データを効率的に処理して、自然言語による問い合わせに対応するシステムを作成します。
コンポーネントの相互作用
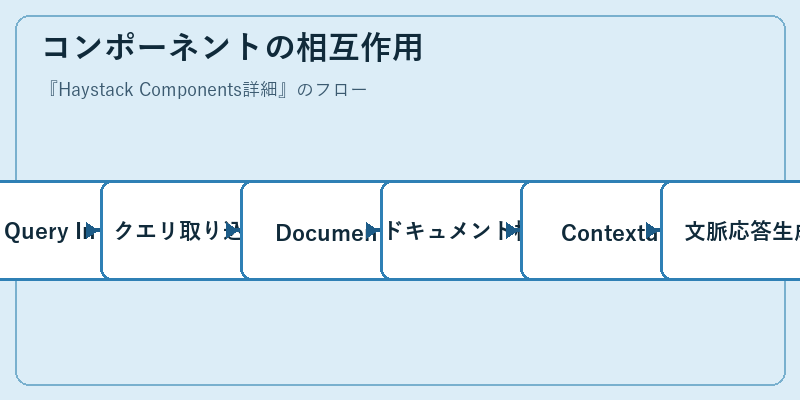
Haystackのフローは、ユーザーからの問いを受け取り、関連する情報を収集し、最終的に最適な回答を生成します。
これにより、質問に対する即座かつ正確な答えが可能になり、知識ベースのシステムに革命をもたらしました。
アーキテクチャの歴史と進化

HaystackはELI5やBERTなどの先行プロジェクトから始まり、独自のアプローチを確立しました。
各段階で強化された機能と性能が、現在のフレームワーク形成に繋がっています。
Haystackとその他のシステム比較
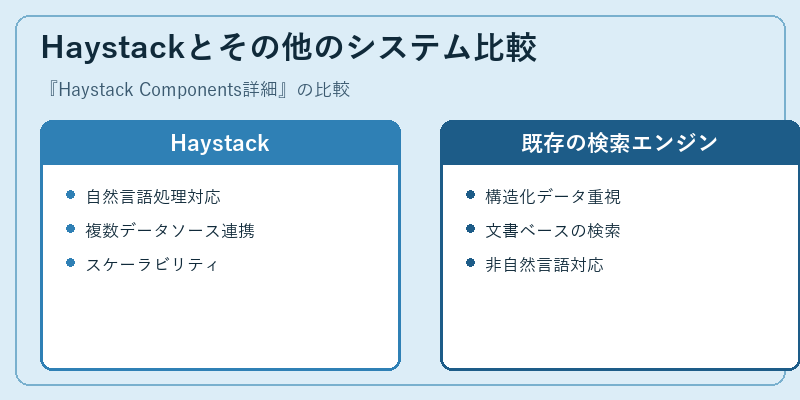
Haystackは、その柔軟性と高度な機能を活かし、従来型の検索エンジンにない新たな価値を提供しています。
一方で、既存システムも独自の強みを持っており、選択は用途やニーズによって異なります。
まとめ
Haystack Components詳細の理解により、自然言語プロセッシングと情報検索における新たな可能性が広がります。フレームワークの進化を続けていこう
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







