
ヒープファイルは、データベースシステムにおいてデータの追加や削除が頻繁に行われるための効率的なストレージメカニズムです。その歴史と原理を紐解きつつ、現在のデータ管理における重要な役割を探ります。
この記事の目次
- ヒープファイルの定義
- ヒープファイルの歴史
- ヒープファイルの内部構造
- ヒープファイルとBツリーの比較
- まとめ
ヒープファイルの定義
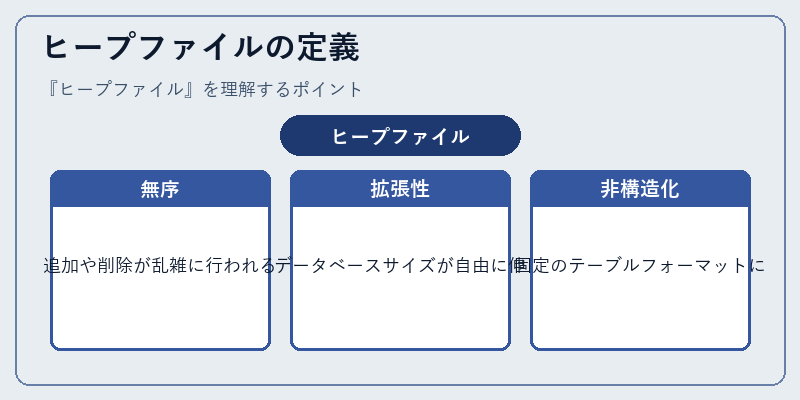
ヒープファイルは、特定の順序を持たないデータレコードの集合体を指します。データベースシステムで重要な要素ですが、その実態や機能については定義が曖昧です。
例えば、MySQLのようなDBMSでは、ヒープテーブルと呼ばれる非パーシステントな記憶領域を使用しています。これは一時的なキャッシュとしても利用可能で、速度向上に寄与します。
ヒープファイルの歴史
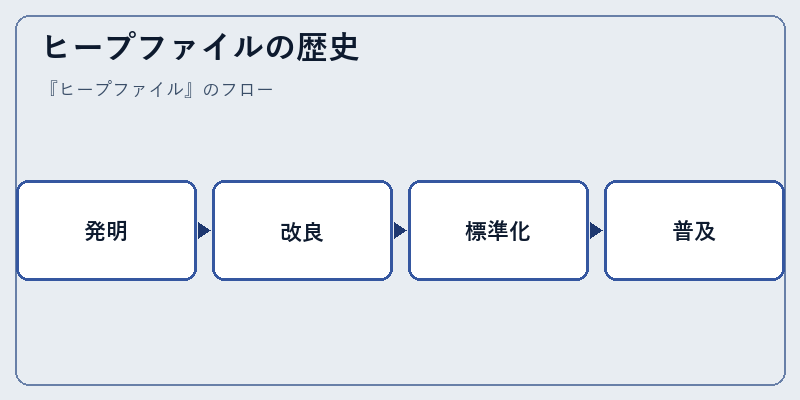
ヒープファイルの概念は、1970年代にデータ管理技術が急速に進歩する時期に生まれました。それ以前では、テーブルベースのストレージしか存在せず、効率性と柔軟性の面で限界がありました。
その後、データベース理論における重要な発展により、ヒープファイルは多くの実用的なアプリケーションに利用されるようになりました。
ヒープファイルの内部構造

ヒープファイルは、単一の大きな連続した領域としてではなく、複数の小さな物理セクションで構成されることが多いです。これはデータの一貫性とパフォーマンスを確保するための重要な要素です。
これらのセクションはそれぞれ特定のローカリゼーションルールに従って管理されますが、全体として論理的には分散したデータストアとして機能します。
ヒープファイルとBツリーの比較
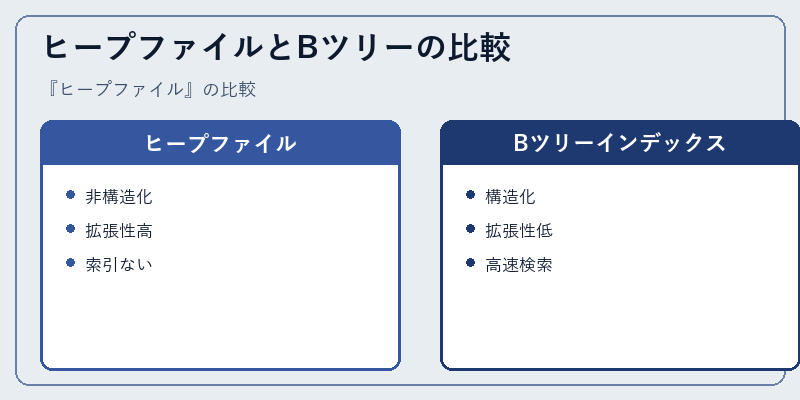
ヒープファイルとBツリーインデックスは、データベースの異なるアプローチを提供します。ヒープファイルは柔軟で容易な拡張が可能ですが、効率的な検索には適していません。
一方、Bツリーは厳格な構造を持ちながら高速にデータアクセスが可能な反面、拡張性や柔軟性には劣ります。両者の特性を理解することは、最適なデータ管理戦略の立案に役立ちます。
まとめ
ヒープファイルは、動的なデータ環境において重要な役割を果たしますが、その一方で構造化されたインデックスとのバランスを考えることが求められます。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







