
Huber Lossは、機械学習モデルの訓練において、平均二乗誤差と絶対誤差の長所を併せ持つ損失関数として注目を集めています。1960年代にRobust Statisticsという分野が発展した際に考案され、それ以来非線形回帰分析や異常検出など広範な応用範囲を持っています。
この記事の目次
- Huber Lossの定義
- Huber Lossと平均二乗誤差の違い
- Huber Lossの計算方法
- Huber Lossの応用例
- まとめ
Huber Lossの定義
Huber Lossは、二乗損失と絶対値損失の長所を統合したものです。これにより、平均二乗誤差が過剰に反応する極端なデータ点でも安定性を維持します。
例えば、線形回帰モデルにおいてHuber Lossを使用すると、外れ値に対する影響を最小限に抑えつつ、精度の高い予測を得ることが可能になります。
Huber Lossと平均二乗誤差の違い
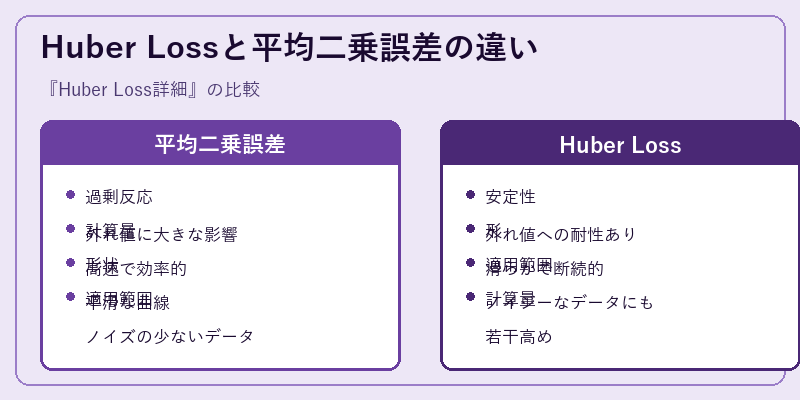
Huber Lossは、平均二乗誤差と比べて外れ値に対する影響が小さく、全体の訓練を安定化させます。
一方で、平均二乗誤差はノイズの少ないデータセットに対して効果的ではありますが、極端な偏差が大きな問題になる可能性があります。
Huber Lossの計算方法

Huber Lossは、まず予測値と実際の値との差(即ち誤差)を計算します。その後、この誤差が一定以上の大きさであれば絶対誤差を使用し、小さければ二乗誤差を適用するという流れで損失を決定します。
具体的には、カットオフ距離δが定義され、これが超える場合のみ絶対誤差の計算に移行することで、平滑な曲線と折れ線グラフの間でのスムーズな遷移が可能になります。
Huber Lossの応用例

Huber Lossは、特に回帰問題における外れ値の影響を軽減するために広く採用されています。
また、機械学習アルゴリズムにおいても、損失関数としてHuber Lossを選ぶことでモデルの汎化性能を向上させることが可能です。
まとめ
Huber Lossは機械学習における外れ値処理に有効なツールであり、その特性が様々な応用分野で活用されています。今後も損失関数の進化とともに新たな可能性が広がっていくでしょう。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







