
Hydraは、高いスケーラビリティとパフォーマンスを実現するための分散型データベースアーキテクチャで、2010年代初頭に開発が始まりました。その特徴的な設計により、多数のノード間での同時処理が可能となり、リアルタイム分析や大規模なデータ処理における効率性を向上させています。
この記事の目次
- Hydraのアーキテクチャと機能
- Hydraが解決した問題
- Hydraの内部仕組み
- Hydraと他のデータベースの比較
- まとめ
Hydraのアーキテクチャと機能

Hydraの特徴は、分散型クラスタリングと並列処理の組み合わせで成り立つ。これにより、システム全体が複数のノードにまたがる大規模データベースを効率的に管理することが可能となる。
具体的には、各ノード間での負荷分散を通じてスループットと応答時間を改善する。このアーキテクチャは、高度なリアルタイム分析や大量のトランザクション処理に対忞し易く設計されている。
Hydraが解決した問題

Hydraは、従来のデータベースシステムが直面する課題を解決するために考案された。その中でも最も重要な点は、単一障害点問題とネットワーク遅延によるパフォーマンス低下だ。
これにより、複数ノード間での冗長化や同期処理を通じて安定性と信頼性を向上させることが可能となった。また、高速なデータ転送技術の導入もこのアーキテクチャの一環として挙げられる。
Hydraの内部仕組み
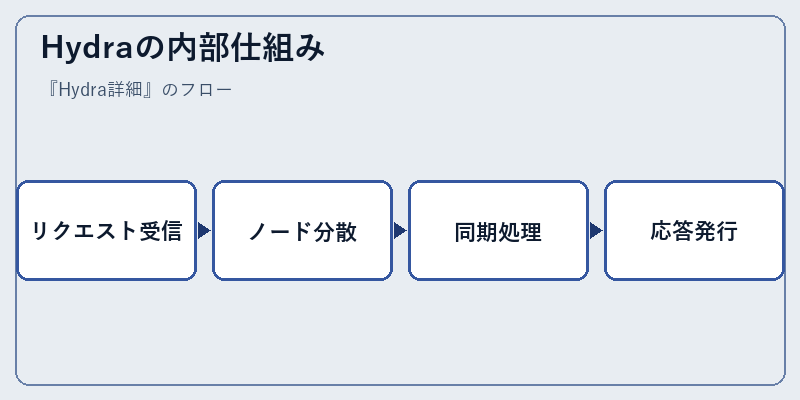
Hydraでは、入力データの効率的な管理と処理を実現するために、複数ノード間で並列処理が行われる。これは、リクエストを分散させることでシステム全体の負荷を均等化し、パフォーマンス向上に寄与する。
この技術は、特に大量データのリアルタイム分析や、高頻度トランザクション環境における問題解決に効果的だ。これは、各ノードが独自に処理を行うことで全体的な応答時間を大幅に短縮させるからである。
Hydraと他のデータベースの比較

Hydraと他の分散型システムを比較すると、その並列処理能力やスケーラビリティが際立つ。これらはハイブリッドクラウド環境や大規模なウェブアプリケーションに最適だ。
一方で従来のデータベースでは中心化した構造が主流であり、それがシステムの性能と柔軟性を制約する傾向がある。これに対しHydraは並列処理によりこれらの課題を解決し、より広範囲なアプリケーションに対応できる。
まとめ
Hydraは高負荷環境におけるデータベースシステムのパフォーマンスと信頼性向上に大きく貢献する技術であり、その仕組みや特性を理解することで、より効果的なデータ管理戦略が立案可能となる。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。







