
RAG(Retrieval-Augmented Generation、検索拡張生成)は、外部の知識源を検索した結果を生成モデルのプロンプトに差し込み、事実根拠を補強しながら回答を生成する手法です。Facebook AI Research(FAIR、現Meta AI)のパトリック・ルイス、エチエンヌ・ペレらが2020年5月に発表した論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」が起源で、ChatGPTが普及した2023年以降、社内ナレッジを安全に使うための主要アーキテクチャとして急速に標準化されました。今ではLangChain、LlamaIndex、Vertex AI、Azure AI Searchなど主要プラットフォームの中心概念となっています。
この記事の目次
- 検索器と生成器のコンビ
- 2020年のFAIR論文から普及まで
- 典型的なRAG構築の流れ
- ファインチューニングとの使い分け
- まとめ
検索器と生成器のコンビ
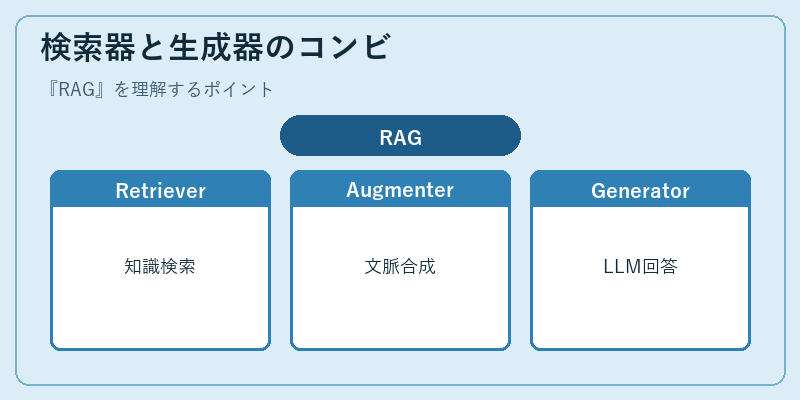
RAGの基本構造は、Retriever(検索器)とGenerator(生成器)の2要素から成ります。ユーザーから質問が来ると、まずRetrieverがその意味を表す埋め込みベクトルを使ってベクトルDBや全文検索DBから関連ドキュメントを取り出します。次に取り出した文書片(チャンク)を生成器のプロンプトに「これらを参考にして答えなさい」という形で差し込み、最後にLLMが回答を生成します。「LLMの知識」だけでは古い・偏る・誤るという問題を、外部知識の参照で補うのが核心です。
実装上は、検索の正確性と生成の自然さの両立が肝になります。ハイブリッド検索(密ベクトル+疎ベクトル)、再ランク(リランカー)、HyDE(仮想回答を作って検索する手法)など、Retriever側の工夫が盛んに研究されています。生成側ではプロンプトのテンプレート設計、引用付与、ハルシネーション検出など、回答品質を保つ仕掛けが組み合わさり、総合的に「事実根拠つきの応答」を成立させる仕組みになっています。
2020年のFAIR論文から普及まで
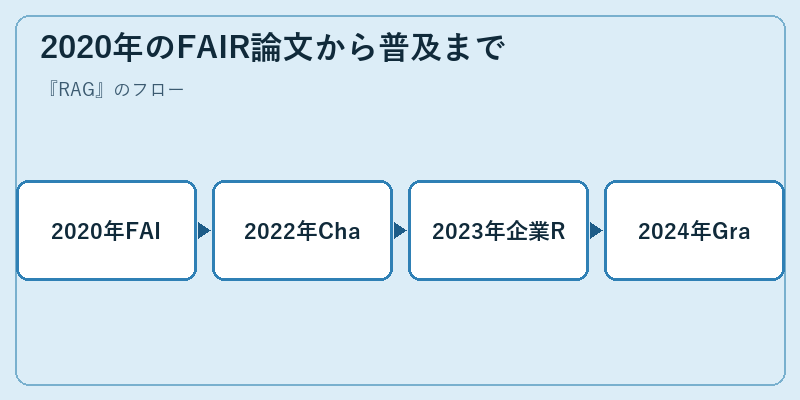
RAGの概念自体は、2020年5月にarXivへ投稿されたFAIRの論文で初めて体系化されました。DPR(Dense Passage Retrieval)と呼ばれる密ベクトル検索を組み合わせ、BARTを生成器に使うことで、オープンドメインQAタスクで当時の最先端を更新したことが注目を集めました。とはいえ当時はまだ研究界隈の手法という位置付けで、産業界への浸透は限定的でした。
潮目が変わったのは2022年末のChatGPT公開以降です。「LLMはすごいが事実を間違える」という課題に直面した企業が、社内データを使った回答精度向上の手段として一斉にRAGへ注目し、2023年にはRAGがLLM応用アーキテクチャの主流となりました。Microsoft Copilot、Azure AI Search、Google Vertex AI Searchなど主要クラウドが標準でRAGをサポートし、2024年以降はナレッジグラフを使うGraph RAG、エージェントが自律的に検索手段を選ぶAgentic RAGなど、より高度な派生形が登場しています。
典型的なRAG構築の流れ

実務でのRAG構築は、おおむね5ステップで進みます。まずPDF・HTML・Word・Notion・Confluenceなどから対象ドキュメントを取り込み、500~1,500トークン程度の意味あるチャンクに分割します。次にOpenAI text-embedding-3、Cohere Embed、Voyage AI、Gemini Embeddings、bge-large-jaなどの埋め込みモデルでチャンクをベクトル化し、Pinecone、Weaviate、Qdrant、Chroma、Milvus、pgvectorといったベクトルDBに格納します。
ユーザー質問が来たら、同じ埋め込みモデルでクエリをベクトル化し、ベクトルDBで類似度検索を行い、上位数件のチャンクを「コンテキスト」としてLLMに与えます。より高度な構成では、検索結果をリランカーで並び替え、複数の検索戦略を統合し、引用付き回答を作り、ユーザーが原文へ遡れるようにします。LangChainやLlamaIndexはこの一連のパイプラインを抽象化しており、PoCなら数十行、本番運用でも数百行で構築できる時代になりました。「LLMの幻覚を抑え、社内知識を最新に保つ」用途のデファクトです。
ファインチューニングとの使い分け
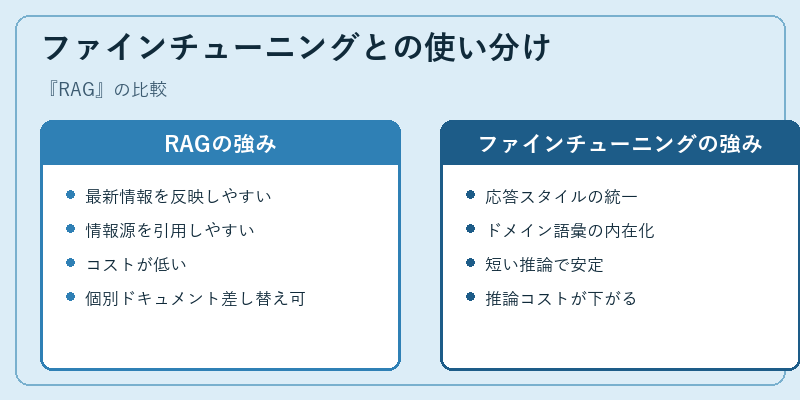
RAGはしばしばファインチューニング(モデル本体の再学習)と比較されます。RAGはモデル本体を変えず、外部知識を都度差し込む手法なので、ドキュメントを追加・修正するだけで応答に反映できます。情報源を引用させやすく、コストも比較的低めです。一方でファインチューニングは、特定ドメインの語彙・スタイル・出力形式を学習し、推論時のプロンプトを短くできるなどの強みがあります。
実際の現場では両者は対立せず、組み合わせて使われることが多いです。「文体や禁則をファインチューニングで仕込み、最新の事実はRAGで補う」というハイブリッド構成は典型です。また、RAGの精度をさらに上げるためにEvaluation/LangSmith/Trulensなどの評価ツールでパラメータを継続的に調整するMLOpsも整いつつあります。「事実根拠を持つLLMアプリ」を成立させる基本骨格として、RAGはLLM時代の代表的アーキテクチャパターンであり続けるでしょう。
まとめ
RAGは2020年にFAIRが提唱し、ChatGPT登場後に企業向けLLM活用の中核となった検索拡張生成手法です。Retrieverで関連知識を取り出し、Generatorに根拠付きで答えさせる構造は、ベクトルDBや各種フレームワークと結びつきながら、LLM時代の標準アーキテクチャとして広く採用されています。
※本記事はIT用語辞典の手書きドラフトです。公開前に最新情報・出典を確認のうえ加筆修正してください。








コメント